

モリカトロン株式会社運営「エンターテインメント×AI」の最新情報をお届けするサイトです。
- TAG LIST
- CGCGへの扉安藤幸央生成AI月刊エンタメAIニュース機械学習河合律子ディープラーニング吉本幸記OpenAIGAN音楽NVIDIAChatGPTGoogle強化学習三宅陽一郎森川幸人グーグルStable Diffusionニューラルネットワーク大規模言語モデルLLMシナリオDeepMind人工知能学会モリカトロンマイクロソフトQAAIと倫理GPT-3自然言語処理Facebook大内孝子倫理映画著作権ルールベースアートゲームプレイAIキャラクターAIスクウェア・エニックス敵対的生成ネットワークSIGGRAPHモリカトロンAIラボインタビューNPC画像生成NFTMinecraftロボットDALL-E2音楽生成AIプロシージャルMidjourneyデバッグファッションStyleGAN自動生成ディープフェイク遺伝的アルゴリズム画像生成AIゲームAIVFXAdobeテストプレイメタAIアニメーションテキスト画像生成深層学習CEDEC2019MicrosoftデジタルツインメタバースVR小説ボードゲームDALL-ECLIPtoioビヘイビア・ツリーマンガCEDEC2021CEDEC2020作曲不完全情報ゲームロボティクスナビゲーションAIマインクラフト畳み込みニューラルネットワークスポーツエージェントGDC 2021GPT-4手塚治虫マルチモーダル汎用人工知能JSAI2022バーチャルヒューマンNVIDIA OmniverseGDC 2019動画生成AIマルチエージェントCEDEC2022MetaAIアート3DCGStability AIメタデジタルヒューマン懐ゲーから辿るゲームAI技術史教育ジェネレーティブAIはこだて未来大学プロンプトRed Ram栗原聡CNNNeRFDALL-E 3BERTMicrosoft AzureUnityOmniverseJSAI2023ELSI鴫原盛之HTN階層型タスクネットワークソニー東京大学JSAI2020GTC20233DマーケティングTensorFlowインタビューブロックチェーンCMイベントレポートアストロノーカ模倣学習対話型エージェントAmazonトレーディングカードメディアアートDQN高橋力斗合成音声水野勇太アバターブラック・ジャックUbisoftGenvid TechnologiesガイスターStyleGAN2電気通信大学稲葉通将ARアップルGTC2022GPT-3.5SoraSIGGRAPH ASIANetflixJSAI2021Bard研究シムピープル世界モデルMCS-AI動的連携モデルマーダーミステリーモーションキャプチャーアドベンチャーゲームTEZUKA2020CEDEC2023AGIテキスト生成インディーゲームElectronic Arts音声合成広告JSAI2024メタデータGDC Summerイーロン・マスクStable Diffusion XL森山和道キャリアeスポーツスタンフォード大学アーケードゲームテニスサイバーエージェント音声認識類家利直eSportsBLUE PROTOCOLシーマンaiboSIE大澤博隆SFプロトタイピングモリカトロン開発者インタビュー宮本茂則チャットボットGeminiワークショップEpic GamesAIロボ「迷キュー」に挑戦AWS徳井直生村井源クラウド斎藤由多加AlphaZeroTransformerGPT-2rinnaAIりんなカメラ環世界中島秀之PaLMGitHub Copilot哲学ベリサーブPlayable!ハリウッド理化学研究所Gen-1SFテキスト画像生成AI松尾豊AIQVE ONEデータマイニング現代アートDARPAドローンシムシティゲームエンジンImagenZorkバイアスASBSぱいどんAI美空ひばり手塚眞バンダイナムコ研究所スパーシャルAIELYZANEDOFSM-DNNMindAgentLEFT 4 DEAD通しプレイ論文OpenAI Five本間翔太馬淵浩希CygamesAudio2Faceピクサープラチナエッグイーサリアム効果音ボエダ・ゴティエビッグデータ中嶋謙互Amadeus Codeデータ分析MILENVIDIA ACEナラティブNVIDIA RivaOmniverse ReplicatorWCCFレコメンドシステムNVIDIA DRIVE SimWORLD CLUB Champion FootballNVIDIA Isaac Simセガ柏田知大軍事田邊雅彦Google I/Oトレカ慶應義塾大学Max CooperGPTDisneyFireflyPyTorch京都芸術大学ChatGPT4モンテカルロ木探索眞鍋和子バンダイナムコスタジオヒストリアAI Frog Interactive新清士田中章愛銭起揚齊藤陽介コナミデジタルエンタテインメント成沢理恵お知らせMagic Leap OneTencentサッカーバスケットボールTikTokSuno AItext-to-imageサルでもわかる人工知能text-to-3DVAEDreamFusionTEZUKA2023リップシンキングRNNUbisoft La Forge自動運転車知識表現ウォッチドッグス レギオンVTuberIGDA立教大学秋期GTC2022市場分析フォートナイトKLabどうぶつしょうぎRobloxジェイ・コウガミ音楽ストリーミングMIT野々下裕子Adobe MAXマシンラーニング5GMuZeroRival Peakがんばれ森川君2号pixivオムロン サイニックエックスGPTs対話エンジンポケモン3Dスキャン橋本敦史リトル・コンピュータ・ピープルCodexシーマン人工知能研究所コンピューティショナル・フォトグラフィーPreferred Networksゴブレット・ゴブラーズ絵画Open AI3D Gaussian SplattingMicrosoft DesignerイラストシミュレーションSoul Machines柿沼太一完全情報ゲームバーチャルキャラクター坂本洋典宮本道人釜屋憲彦ウェイポイントLLaMAパス検索Hugging Face対談藤澤仁生物学GTC 2022xAIApple Vision Pro画像認識SiemensストライキStyleCLIPDeNAVoyager長谷洋平GDC 2024クラウドコンピューティングmasumi toyotaIBM宮路洋一OpenSeaGDC 2022SNSTextWorldEarth-2AppleBingMagentaソフトバンクYouTube音声生成AIELYZA PencilScenarioSIGGRAPH2023AIピカソGTC2021AI素材.comCycleGANテンセントAndreessen HorowitzQA Tech Night松木晋祐NetHack下田純也桑野範久キャラクターモーションControlNet音源分離NBAフェイクニュースユニバーサルミュージックRPG法律Web3SIGGRAPH 2022レベルデザインDreamerV3AIボイスアクターUnreal Engine南カリフォルニア大学NVIDIA CanvasGPUALife人工生命オルタナティヴ・マシンサム・アルトマンサウンドスケープLaMDATRPGマジック:ザ・ギャザリングAI Dungeon介護ゲーム背景アパレル不気味の谷ナビゲーションメッシュデザイン写真高橋ミレイ深層強化学習松原仁松井俊浩武田英明フルコトELYZA DIGESTWWDCWWDC 2024建築西成活裕ハイブリッドアーキテクチャAI野々村真Apex LegendsELIZA群衆マネジメントライブポートレイトNinjaコンピュータRPGライブビジネスWonder StudioAdobe Max 2023GPT-4-turboアップルタウン物語新型コロナ土木佐藤恵助KELDIC周済涛BIMBing Chat大道麻由メロディ言語清田陽司インフラBing Image Creator物語構造分析ゲームTENTUPLAYサイバネティックス慶応義塾大学MARVEL Future FightAstro人工知能史Amazon BedrockAssistant with Bard渡邉謙吾タイムラプスEgo4DAI哲学マップThe Arcadeここ掘れ!プッカバスキア星新一X.AISearch Generative Experienceくまうた日経イノベーション・ラボStyleGAN-XLX Corp.Dynalang濱田直希敵対的強化学習StyleGAN3TwitterVLE-CE大柳裕⼠階層型強化学習GOSU Data LabGANimatorXホールディングス加納基晴WANNGOSU Voice AssistantVoLux-GANMagiAI Actソニー・インタラクティブエンタテインメント竹内将SenpAI.GGProjected GANEU研究開発事例MobalyticsSelf-Distilled StyleGANSDXLArs Electronica赤羽進亮ニューラルレンダリングRTFKTAI規制遊戯王岡島学AWS SagemakerPLATONIKE欧州委員会UDI(Universal Duel Interface)映像セリア・ホデント形態素解析frame.ioClone X欧州議会第一工科大学UXAWS LambdaFoodly村上隆欧州理事会佐竹空良誤字検出MusicLM小林篤史認知科学中川友紀子Digital MarkAudioLM九州大学ゲームデザインSentencePieceアールティSnapchatMusicCaps荻野宏実LUMINOUS ENGINEクリエイターコミュニティAudioCraft伊藤黎Luminous ProductionsBlenderBot 3バーチャルペットビヘイビアブランチパターン・ランゲージ竹村也哉Meta AINVIDIA NeMo ServiceMubertWPPちょまどマーク・ザッカーバーグヴァネッサ・ローザMubert RenderGeneral Computer Control(GCC)GOAPWACULVanessa A RosaGen-2CradleAdobe MAX 2021陶芸Runway AI Film Festival自動翻訳Play.htPreViz音声AIAIライティングLiDARCharacter-LLMOmniverse AvatarAIのべりすとPolycam復旦大学FPSQuillBotdeforumChat-Haruhi-Suzumiyaマルコフ決定過程NVIDIA MegatronCopysmith涼宮ハルヒNVIDIA MerlinJasperハーベストEmu VideoNVIDIA MetropolisForGamesNianticパラメータ設計ゲームマーケットペリドットバランス調整岡野翔太Dream Track協調フィルタリング郡山喜彦Music AI Tools人狼知能テキサス大学ジェフリー・ヒントンLyriaGoogle I/O 2023Yahoo!知恵袋AlphaDogfight TrialsAI Messenger VoicebotインタラクティブプロンプトAIエージェントシミュレーションOpenAI Codex武蔵野美術大学StarCraft IIHyperStyleBingAI石渡正人Future of Life InstituteRendering with Style手塚プロダクションIntel林海象LAIKADisneyリサーチヴィトゲンシュタインPhotoshop古川善規RotomationGauGAN論理哲学論考Lightroom大規模再構成モデルGauGAN2CanvaLRMドラゴンクエストライバルズ画像言語表現モデルObjaverse不確定ゲームSIGGRAPH ASIA 2021PromptBaseBOOTHMVImgNetDota 2ディズニーリサーチpixivFANBOXOne-2-3-45Mitsuba2バンダイナムコネクサス虎の穴3DガウシアンスプラッティングソーシャルゲームEmbeddingワイツマン科学研究所ユーザーレビューFantiaワンショット3D生成技術GTC2020CG衣装mimicとらのあなNVIDIA MAXINEVRファッションBaidu集英社FGDC淡路滋ビデオ会議ArtflowERNIE-ViLG少年ジャンプ+Future Game Development ConferenceグリムノーツEponym古文書ComicCopilot佐々木瞬ゴティエ・ボエダ音声クローニング凸版印刷コミコパGautier Boeda階層的クラスタリングGopherAI-OCRゲームマスター画像判定Inowrld AIJulius鑑定ラベル付けMODAniqueTPRGOxia PalusGhostwriter中村太一バーチャル・ヒューマン・エージェントtoio SDK for UnityArt RecognitionSkyrimエグゼリオクーガー実況パワフルサッカースカイリムCopilot石井敦NHC 2021桃太郎電鉄RPGツクールMZComfyUI茂谷保伯池田利夫桃鉄ChatGPT_APIMZserial experiments lainGDMC新刊案内パワサカダンジョンズ&ドラゴンズAI lainマーベル・シネマティック・ユニバースOracle RPGPCGMITメディアラボMCU岩倉宏介深津貴之PCGRLアベンジャーズPPOxVASynthDungeons&Dragonsマジック・リープDigital DomainMachine Learning Project CanvasLaser-NVビートルズMagendaMasquerade2.0国立情報学研究所ザ・ビートルズ: Get BackノンファンジブルトークンDDSPフェイシャルキャプチャー石川冬樹MERFDemucsスパコンAlibaba音楽編集ソフト里井大輝KaggleスーパーコンピュータVQRFAdobe Audition山田暉松岡 聡nvdiffreciZotopeAssassin’s Creed OriginsAI会話ジェネレーターTSUBAME 1.0NeRFMeshingRX10Sea of ThievesTSUBAME 2.0LERFMoisesGEMS COMPANYmonoAI technologyLSTMABCIマスタリングモリカトロンAIソリューション富岳レベルファイブ初音ミクOculusコード生成AISociety 5.0リアム・ギャラガー転移学習テストAlphaCode夏の電脳甲子園グライムスKaKa CreationBaldur's Gate 3Codeforces座談会BoomyVOICEVOXCandy Crush Saga自己増強型AIジョン・レジェンドGenie AISIGGRAPH ASIA 2020COLMAPザ・ウィークエンドSIGGRAPH Asia 2023ADOPNVIDIA GET3DドレイクC·ASEデバッギングBigGANGANverse3DFLAREMaterialGANダンスグランツーリスモSPORTAI絵師エッジワークスMagicAnimateReBeLグランツーリスモ・ソフィーUGC日本音楽作家団体協議会Animate AnyoneGTソフィーPGCFCAインテリジェントコンピュータ研究所VolvoFIAグランツーリスモチャンピオンシップVoiceboxアリババNovelAIさくらインターネットDreaMovingRival PrakDGX A100NovelAI DiffusionVISCUITぷよぷよScratchユービーアイソフトWebcam VTuberモーションデータスクラッチ星新一賞大阪公立大学ビスケット北尾まどかHALOポーズ推定TCGプログラミング教育将棋メタルギアソリッドVメッシュ生成FSMメルセデス・ベンツQRコードVALL-EMagic Leap囲碁Deepdub.aiナップサック問題Live NationEpyllionデンソーAUDIOGEN汎用言語モデルWeb3.0マシュー・ボールデンソーウェーブEvoke MusicAIOpsムーアの法則原昌宏AutoFoleySpotifyスマートコントラクト日本機械学会Colourlab.AiReplica Studioロボティクス・メカトロニクス講演会ディズニーamuseChitrakarQosmoAdobe MAX 2022トヨタ自動車Largo.ai巡回セールスマン問題かんばん方式Cinelyticジョルダン曲線メディアAdobe ResearchTaskade政治Galacticaプロット生成Pika.artクラウドゲーミングAI Filmmaking Assistant和田洋一リアリティ番組映像解析FastGANStadiaジョンソン裕子セキュリティ4コママンガAI ScreenwriterMILEsNightCafe東芝デジタルソリューションズ芥川賞インタラクティブ・ストリーミングLuis RuizSATLYS 映像解析AI文学インタラクティブ・メディア恋愛PFN 3D ScanElevenLabsタップル東京工業大学HeyGenAbema TVLudo博報堂After EffectsNECラップPFN 4D Scan絵本木村屋SIGGRAPH 2019ArtEmisZ世代DreamUp出版GPT StoreAIラッパーシステムDeviantArtAmmaar Reshi生成AIチェッカーWaifu DiffusionStoriesユーザーローカルGROVERプラスリンクス ~キミと繋がる想い~元素法典StoryBird九段理江FAIRSTCNovel AIVersed東京都同情塔チート検出Style Transfer ConversationProlificDreamerオンラインカジノRCPUnity Sentis4Dオブジェクト生成モデルRealFlowRinna Character PlatformUnity MuseAlign Your GaussiansiPhoneCALACaleb WardAYGDeep Fluids宮田龍MAV3DMeInGameAmelia清河幸子ファーウェイAIGraphブレイン・コンピュータ・インタフェース西中美和4D Gaussian SplattingBCIGateboxアフォーダンス安野貴博4D-GSLearning from VideoANIMAKPaLM-SayCan斧田小夜Glaze予期知能逢妻ヒカリWebGlazeセコムLLaMA 2NightShadeユクスキュルバーチャル警備システムCode as PoliciesSpawningカント損保ジャパンCaPHave I Been Trained?CM3leonFortnite上原利之Stable DoodleUnreal Editor For FortniteドラゴンクエストエージェントアーキテクチャアッパーグラウンドコリジョンチェックT2I-AdapterXRPAIROCTOPATH TRAVELER西木康智VolumetricsOCTOPATH TRAVELER 大陸の覇者山口情報芸術センター[YCAM]AIワールドジェネレーターアルスエレクトロニカ2019品質保証YCAM日本マネジメント総合研究所Rosebud AI GamemakerStyleRigAutodeskアンラーニング・ランゲージLayer逆転オセロニアBentley Systemsカイル・マクドナルドLily Hughes-RobinsonCharisma.aiワールドシミュレーターローレン・リー・マッカーシーColossal Cave Adventure奥村エルネスト純いただきストリートH100鎖国[Walled Garden]プロジェクトAdventureGPT調査齋藤精一大森田不可止COBOLSIGGRAPH ASIA 2022リリー・ヒューズ=ロビンソンMeta Quest高橋智隆DGX H100VToonifyBabyAGIIPロボユニザナックDGX SuperPODControlVAEGPT-3.5 Turbo泉幸典仁井谷正充変分オートエンコーダーカーリング強いAIロボコレ2019Instant NeRFフォトグラメトリウィンブルドン弱いAIartonomous回帰型ニューラルネットワークbitGANsDeepJoin戦術分析ぎゅわんぶらあ自己中心派Azure Machine LearningAzure OpenAI Serviceパフォーマンス測定Lumiere意思決定モデル脱出ゲームDeepLIoTUNetHybrid Reward Architectureコミュニティ管理DeepL WriteProFitXImageFXウロチョロスSuper PhoenixWatsonxMusicFXProject MalmoオンラインゲームAthleticaTextFX気候変動コーチングProject Paidiaシンギュラリティ北見工業大学KeyframerProject Lookoutマックス・プランク気象研究所レイ・カーツワイル北見カーリングホールWatch Forビョルン・スティーブンスヴァーナー・ヴィンジ画像解析Gemini 1.5気象モデルRunway ResearchじりつくんAI StudioLEFT ALIVE気象シミュレーションMake-A-VideoNTT SportictVertex AI長谷川誠ジミ・ヘンドリックス環境問題PhenakiAIカメラChat with RTXBaby Xカート・コバーンエコロジーDreamixSTADIUM TUBESlackロバート・ダウニー・Jr.エイミー・ワインハウスSDGsText-to-ImageモデルPixelllot S3Slack AIPokémon Battle Scopeダフト・パンクメモリスタAIスマートコーチポケットモンスターGlenn MarshallkanaeruThe Age of A.I.Story2Hallucination音声変換Latitude占いレコメンデーションJukeboxDreambooth行動ロジック生成AIVeap Japanヤン・ルカンConvaiEAPneoAIPerfusionNTTドコモSIFT福井千春DreamIconニューラル物理学EmemeDCGAN医療mign毛髪GenieMOBADANNCEメンタルケアstudiffuse荒牧英治汎用AIエージェント人事ハーバード大学Edgar Handy中ザワヒデキAIファッションウィーク研修デューク大学大屋雄裕インフルエンサー中川裕志Grok-1mynet.aiローグライクゲームAdreeseen HorowitzMixture-of-Experts東京理科大学NVIDIA Avatar Cloud EngineMoE人工音声NeurIPS 2021産業技術総合研究所Replica StudiosClaude 3リザバーコンピューティングSmart NPCsClaude 3 Haikuプレイ動画ヒップホップ対話型AIモデルRoblox StudioClaude 3 Sonnet詩ソニーマーケティングPromethean AIClaude 3 Opusサイレント映画もじぱnote森永乳業環境音暗号通貨note AIアシスタントMusiioC2PAFUZZLEKetchupEndelゲーミフィケーションAlterationAI NewsTomo Kihara粒子群最適化法Art SelfiePlayfool進化差分法オープンワールドArt TransferSonar遊び群知能下川大樹AIFAPet PortraitsSonar+Dtsukurunウィル・ライト高津芳希P2EBlob Opera地方創生大石真史クリムトDolby Atmos吉田直樹BEiTStyleGAN-NADASonar Music Festival素材DETRライゾマティクスSIMASporeクリティックネットワーク真鍋大度OpenAI JapanデノイズUnity for Industryアクターネットワーク花井裕也Voice Engine画像処理DMLabRitchie HawtinCommand R+SentropyGLIDEControl SuiteErica SynthOracle Cloud InfrastructureCPUDiscordAvatarCLIPAtari 100kUfuk Barış MutluGoogle WorkspaceSynthetic DataAtari 200MJapanese InstructBLIP AlphaUdioCALMYann LeCun日本新聞協会立命館大学プログラミング鈴木雅大AIいらすとや京都精華大学ソースコード生成コンセプトアートAI PicassoTacticAIGMAIシチズンデベロッパーSonanticColie WertzEmposyNPMPGitHubCohereリドリー・スコットAIタレントFOOHウィザードリィMCN-AI連携モデル絵コンテAIタレントエージェンシーGPT-4oUrzas.aiストーリーボードmodi.aiProject Astra大阪大学BitSummitGoogle I/O 2024西川善司並木幸介KikiBlenderBitSummit Let’s Go!!Gemma 2サムライスピリッツ森寅嘉Zoetic AIVeoゼビウスSIGGRAPH 2021ペット感情認識ストリートファイター半導体Digital Dream LabsPaLM APIデジタルレプリカ音声加工Topaz Video Enhance AICozmoMakerSuiteGOT7マルタ大学DLSSタカラトミーSkebsynthesia田中達大山野辺一記NetEaseLOVOTDreambooth-Stable-DiffusionHumanRFInworld AI大里飛鳥DynamixyzMOFLINActors-HQMove AIRomiGoogle EarthSAG-AFTRAICRA2024U-NetミクシィGEPPETTO AIWGAIEEE13フェイズ構造ユニロボットStable Diffusion web UIチャーリー・ブルッカー大規模基盤モデルADVユニボPoint-EToroboXLandGato岡野原大輔東京ロボティクスAI model自己教師あり学習インピーダンス制御DEATH STRANDINGAI ModelsIn-Context Learning(ICL)深層予測学習Eric Johnson汎用強化学習AIZMO.AILoRA日立製作所MOBBY’Sファインチューニング早稲田大学Oculus Questコジマプロダクションロンドン芸術大学モビーディックグランツーリスモ尾形哲也生体情報デシマエンジンGoogle Brainダイビング量子コンピュータAIRECSound Controlアウトドアqubit汎用ロボットSYNTH SUPERAIスキャニングIBM Quantum System 2オムロンサイニックエックス照明Maxim PeterKarl Sims自動採寸北野宏明ViLaInJoshua RomoffArtnome3DLOOKダリオ・ヒルPDDLハイパースケープICONATESizerジェン・スン・フアンニューサウスウェールズ大学山崎陽斗ワコールHuggingFaceClaude Sammut立木創太スニーカーStable Audioオックスフォード大学浜中雅俊UNSTREET宗教Lars Kunzeミライ小町Newelse仏教杉浦孔明テスラ福井健策CheckGoodsコカ・コーラ田向権GameGAN二次流通食品VASA-1パックマンTesla Bot中古市場Coca‑Cola Y3000 Zero SugarVoxCeleb2Tesla AI DayWikipediaDupe KillerCopilot Copyright CommitmentAniTalkerソサエティ5.0Sphere偽ブランドテラバース上海大学SIGGRAPH 2020バズグラフXaver 1000配信京都大学Apple Intelligenceニュースタンテキ養蜂立福寛東芝Beewiseソニー・ピクチャーズ アニメーション音声解析DIB-R倉田宜典フィンテック感情分析Luma投資Fosters+Partners周 済涛Dream Machine韻律射影MILIZEZaha Hadid ArchitectsステートマシンNTT韻律転移三菱UFJ信託銀行ディープニューラルネットワークPerplexity
【CEDEC2021】ゲーム制作をAIで効率化するCygamesのチャレンジ
2021.10.26ゲーム

CEDEC2021で行われたセッション「ゲーム制作効率化のためのAIによる画像認識・自然言語処理への取り組み」でCygamesの立福寛氏が講演したのは、社内の共通基盤ツールへのAI機能の導入についてです。AIモデルの学習プロセスについてはもちろん、インフラ構築、作業分担、デプロイ環境など、機能を支える背景の部分も取り上げた、新規にAI導入する際に非常に参考になる内容になっています。
物体検出/画像認識アルゴリズムを利用した自動タグ付け
まず取り掛かったのが、画像認識による自動タグ付けです。キャラクターが一人以上ふくまれる画像を入力すると、キャラクターの名前が表示される機能をリソース管理ツールに実装します。リソース管理ツールはWebベースで画像や動画のアップロードと検索閲覧、一括ダウンロードを行うことができます。タグ付けは手動で行っていますが、その作業プロセスにAIを使った自動レコメンド機能を追加します。
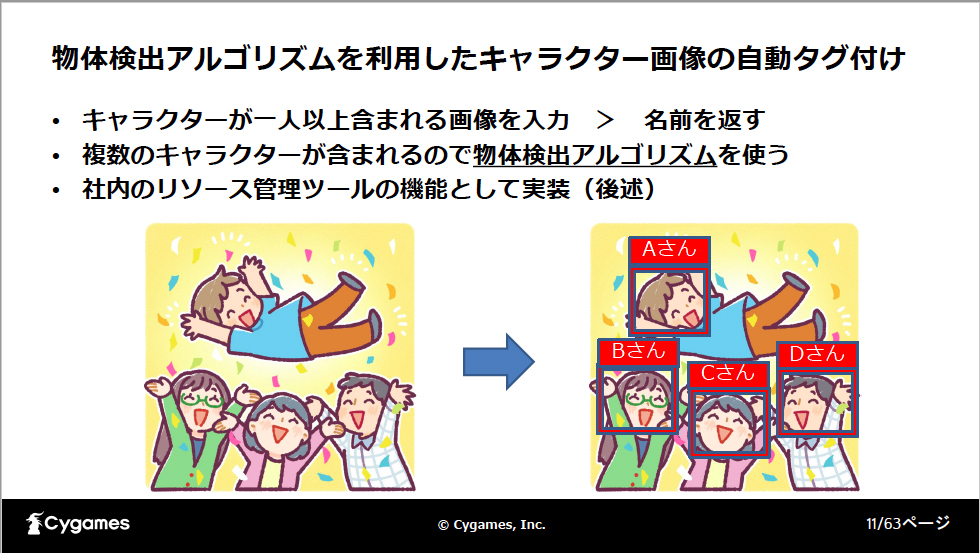
機械学習を用いた一般物体検知のアルゴリズム「SSD(Single Shot Multibox Detector)」を使っています。検出した物体に対しタグ付けを行うというもので、学習を行った後のモデルに画像を与えると物体の領域とクラス名が出力されます。そのうち、今回はクラス名だけをタグとして使用しています。実装にはオープンソースの「PyTorch」を使っています。
学習用のデータはすでに登録された画像データです。複数プロジェクトに使われており、1プロジェクト当たり数千枚の画像が登録されています。そのうち1プロジェクト分の画像を使って学習を行いました。ただ、対象は1キャラクターのみがふくまれる画像となります。これは、2人以上のキャラクターがふくまれた場合にどちらが誰か判別できないためです。今回はキャラクターが200人程度、画像の数はキャラクターごとに差があり、7枚から70枚です。画像に対し、OpenCVのアニメ顔認識モデルを適用し、キャラクターの顔の領域を取り出します。これにより、「画像」と「顔の領域」と「キャラクターの名前」の3つがセットで取得できます。


ローカルPCで1日程度の学習を行ったところ、テストの精度は90%台前半という結果が出ました。これについて立福氏は次のようにまとめています。
- 学習データが多いキャラクターは認識精度が高い(逆も然り)
- 顔や髪型に特徴が少ない一部のキャラクターは誤認識が多い
- 大きくデフォルメされた画像の認識精度は低い(大きくデフォルメされた画像を学習データに入れると精度が大幅に下がった)
そのため、大きくデフォルメされた画像については別のモデルを用意したほうがよいと言えます。また、ゲームのキャラクターに特有の表現、例えば「顔に大きな角度が付いている」「片目が隠れている」などの場合は認識精度が落ちることも指摘しています。
また、背景画像については、画像認識アルゴリズムを使っています。今回はクラウドの機械学習プラットフォーム「AWS Sagemaker」を使って、1,400枚程度の画像データで学習を行いました。分類するクラスは180程度です。実際のデータでの精度は7割ほどです。

自動タグ付け機能のデプロイ環境について
次はデプロイ環境について解説しました。もともとリソース管理ツールはAWS上に構築されているので、AWSで完結できればそれに越したことはありません。そこで、機械学習プラットフォーム「AWS Sagemaker」(以下、Sagemaker)に統一することにしました。
SagemakerはAWS上で機械学習モデルを利用するための統合環境で、さまざまな機械学習モデルの学習からエンドポイントの作成まで行うことができます。前述のように、背景画像のタグ付けに物体検出アルゴリズムをSagemaker上で使っています。キャラクターの顔認識も物体検出アルゴリズムで行います。
最初にオープンソースで組んだ実装より精度が下がったものの、学習データの画像を回転したり拡大縮小などを行いバリエーションを増やすことで解決し、下記の図のようにリソース管理ツールからAPI Gateway→Lambda→Sagemakerという構成で呼び出します。
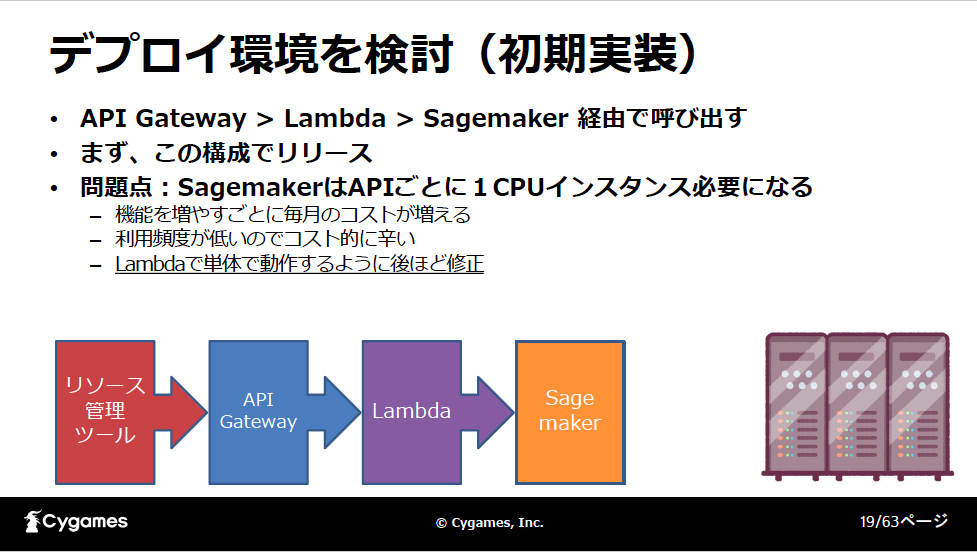
ただし、コスト面で問題が起こったため、最初に使用したオープンソースのSSDの実装をLambda上で動かすよう変更しました。Lambdaでは最大10GBまでユーザーのdockerイメージを動かすことができます。Pythonの機械学習モジュールはデプロイ時に問題になりやすいものの、dockerイメージで丸ごと持っていけるのは非常に楽であるため、お勧めの構成だと立福氏は言います。

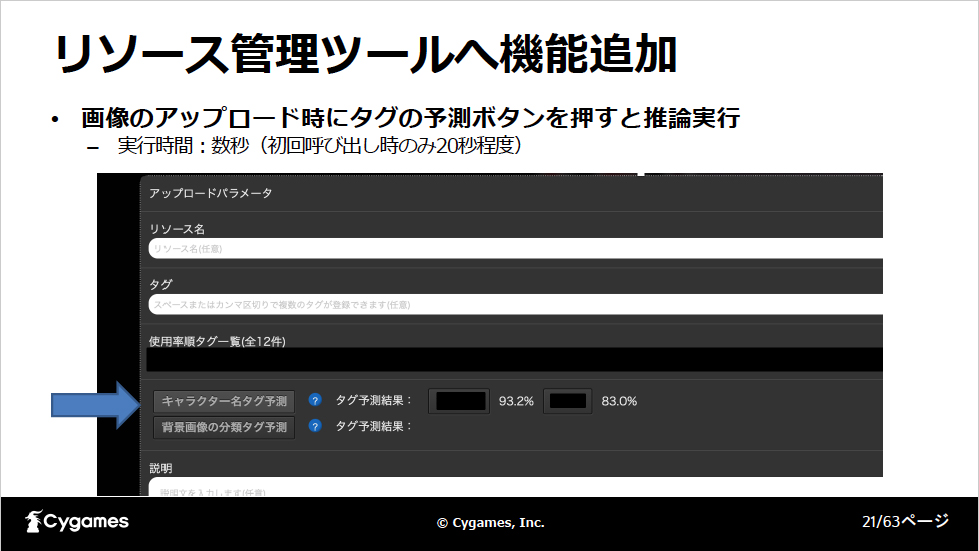
リソース管理ツール上で画像のアップロード中にタグの予測ボタンを押すと、自動タグ付け機能が呼び出され、ダグのレコメンドが行われます。確信度が80%以上の場合のみタグとして出します。自動タグ付け機能の処理は数秒ですが、Lambdaの仕様により初回呼び出し時は20秒程度かかるとのことです。
シナリオ執筆ツールにおける表記揺れ・誤字検出機能
画像への自動タグ付け機能の開発が終わり社内でヒアリングを行ったところ、シナリオ執筆ツールで誤字を検出してほしいという要望が出たことから、次に誤字検出機能を開発することになりました。
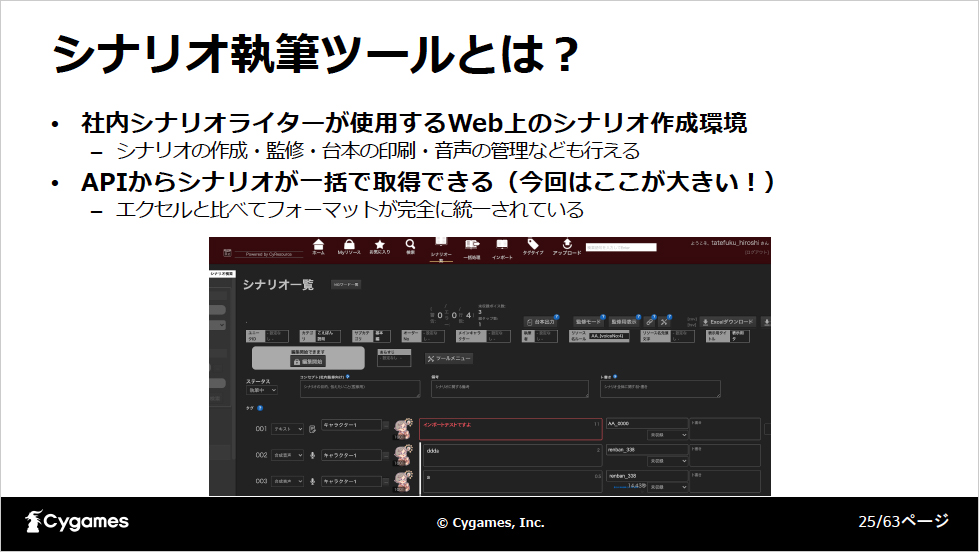
シナリオ執筆ツールはWebベースのシナリオ作成環境で、シナリオの執筆、監修、台本の印刷、音声の管理ができます。Web APIでシナリオを一括で取得することができ、フォーマットも完全に統一されており、AIの学習データを簡単に用意することができます。

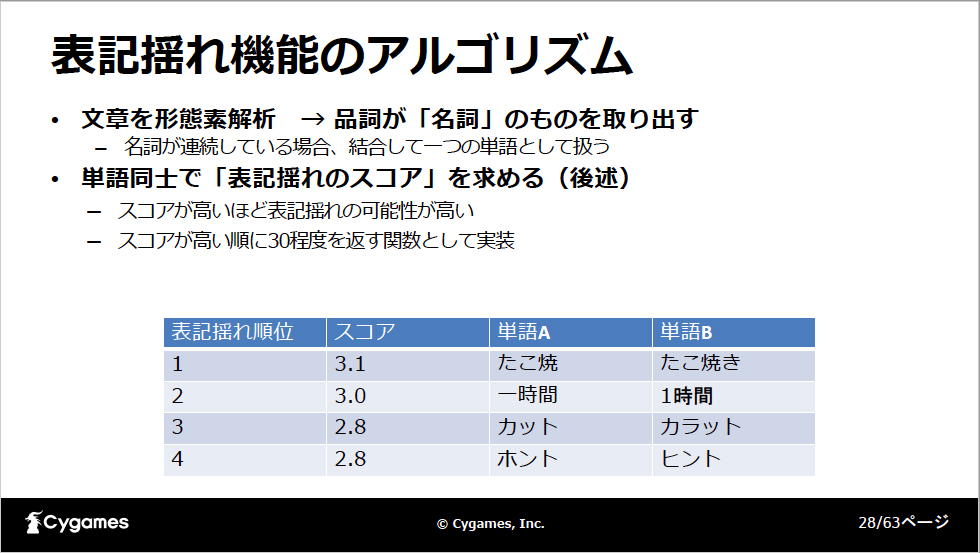
こちらは形態素解析とルールベースでの実装です(参考論文:シナリオ執筆ツールへの表記揺れ機能)。形態素解析とは文章をトークンと呼ばれる単語単位に分割する処理のことで、この形態素解析を使って次のように表記揺れを検出します。まず入力された文章を形態素解析し、名詞を取り出します。この時に連続している名詞は結合して1つの単語として扱います。次に、単語と単語を比較して表記揺れスコアを求めます。このスコアが高いほど表記揺れの可能性が高いことになります。例えば、図のように「たこ焼」「たこ焼き」の表記揺れ、「一時間」「1時間」の表記揺れと判断できます。
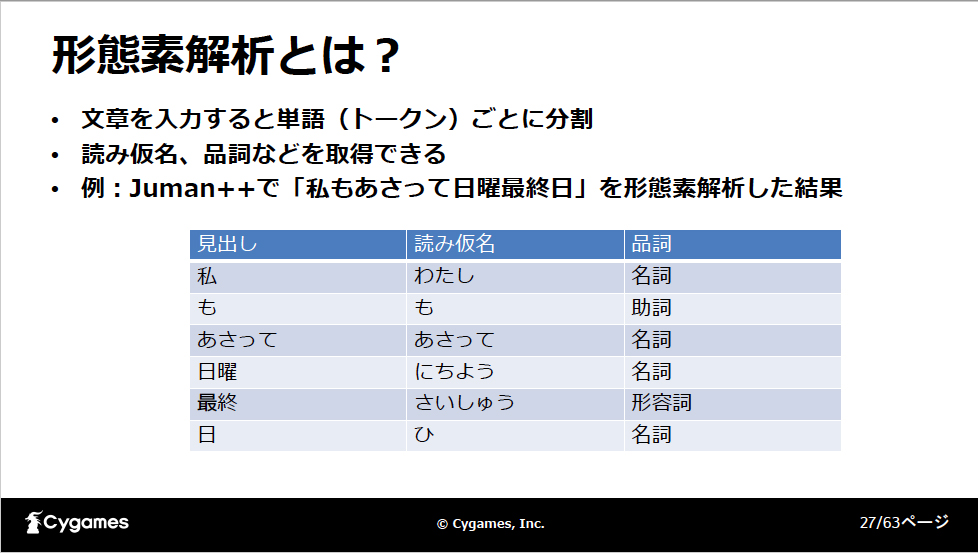
形態素解析モジュールには代表的なものにmecabなどがありますが、比較した結果、juman++を採用しました。juman++はRNNを用いて単語の並びの意味的な自然さを考慮した解析を行う点が特徴で、話し言葉が多いゲームのシナリオには適していると判断したのです。

今回はスコアの高い順に30個を返す関数として実装しました。スコアの計算は先に挙げた論文を参考にしています。この時、計算に必要な要素は「編集距離」と「出現回数」です。単語Aを単語Bにするために必要な手順の数を編集距離とし、単語間の編集距離が小さいほどスコアが大きくなるという仕組みです。また、単語の出現回数の差が大きい場合にスコアが大きくなるようにしています。
例えば「たこ焼き」を「タコ焼」にするには2つの文字を置き換えることになるので編集距離は2です。出現回数も10と1なので、スコアは高くなります。

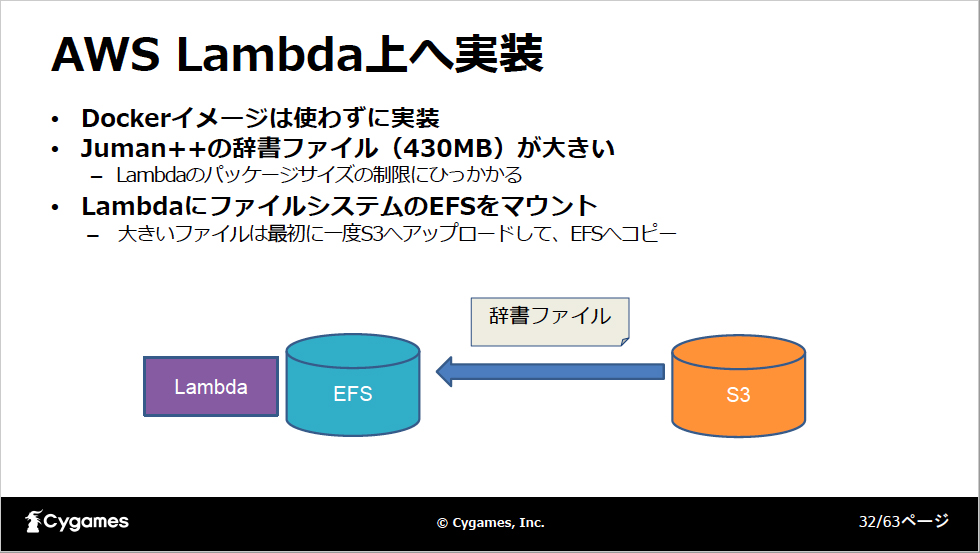
今回はスコアの高い順に30個を返す関数として実装し、AWS Lambdaへ持っていきました。ただ、この機能の開発時はまだLambda上でdockerイメージが使えなかったため、通常のLambdaパッケージを作っています。EFSファイルシステムをLambdaにマウントして、大きいファイルはそちらから読み込んで関数を実行します。
シナリオ執筆ツール上で表記揺れを調べたいシナリオを選択してボタンを押すと、表記揺れ機能のAPIが呼び出されるという仕組みです。表記揺れの可能性がある部分が赤くハイライトされて正しい候補が右側に表示されます。
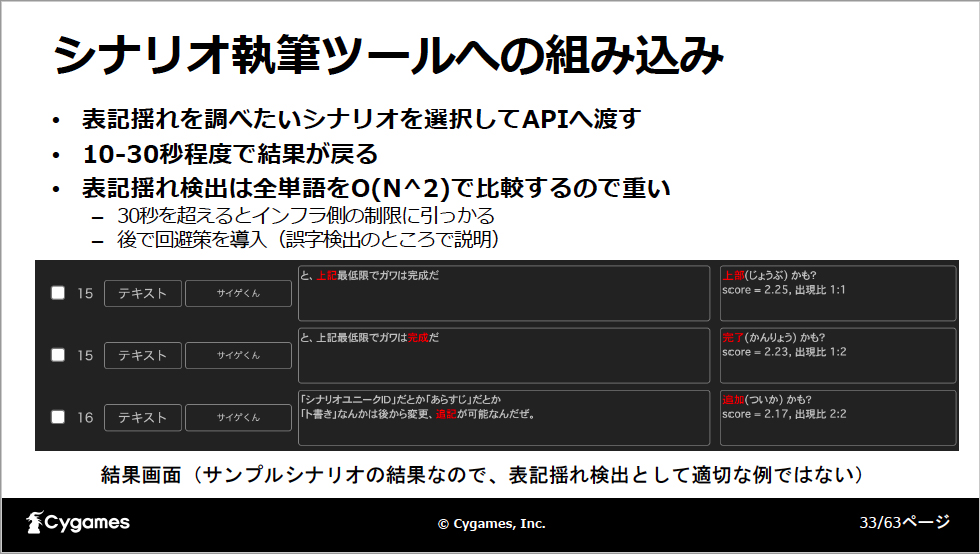
社内のユーザーからも好評で、名詞に加えて動詞の表記揺れ検出機能も欲しいというリクエストにも対応しています。同時に単語を指定して表記揺れを探す機能も追加しました。
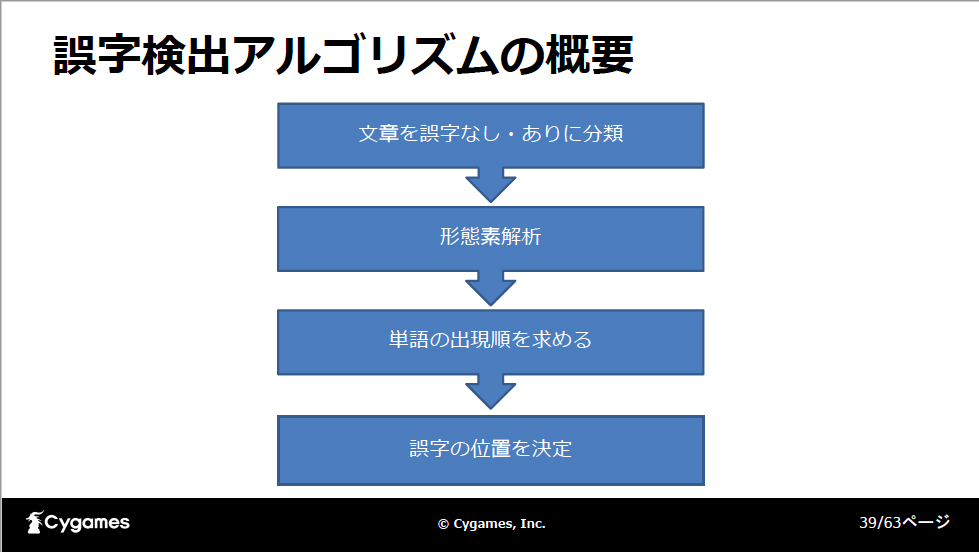
シナリオ執筆ツールにおける誤字検出機能
こちらも社内のユーザーからの要望に応え、開発した機能です。機械学習を利用した誤字検出は有料のサービスが複数存在しますが、毎月の課金がかかるのとデータの機密の問題もあり、独自実装することになりました。論文「Bidirectional LSTMを用いた誤字脱字検出システム」を参考に、一部のアルゴリズムを変更して新たな自然言語処理モデルとして実装しています。
まず自然言語処理モデル「BERT」を使って、入力された文章を「誤字がないもの」と「誤字があるもの」に分類します。次に、誤字があると判断された文章を形態素解析して単語ごとの出現順を別のBERTモデルで求めます。出現順が低い単語は誤字の可能性が高いということになります。単語ごとの出現順をランダムフォレストと呼ばれるモデルに入力して最終的な誤字の位置を求めています。
なお、BERTは2018年にGoogleが発表した自然言語処理モデルで、翻訳や文章分類などのタスクで当時の最高スコアを出したことで一躍有名になりました。今回は文章分類、単語の出現順の推論の2つのタスクに使っています。現在、BERTよりも新しいモデルが出ていますが、広く利用されて情報が多い点と、日本語の学習済みモデルが複数公開されていることが利点です。
各機械学習モデルの説明になりますが、「文章を誤字なし・ありに分類する」モデルにはBERTの文書分類タスクが使われています。学習データとして、ニュース記事とジャンルの組み合わせを用意して学習させ、学習済みのBERTへニュース記事を入力すると適切なジャンルが取得されるというものです。ここでは「誤字がない文章」と「誤字がある文章」の2種類を分類するBERTモデルを作ります。実装はBERTとTensorflow、形態素解析はSentencePieceという構成です。
学習データは「誤字なし」と「誤字あり」の2つ、元の文章と誤字をふくむ文章を1:5で用意してBERTの文章分類で学習させます。誤字のパターンはシナリオ執筆ツールを利用している社内のユーザーから文章校正のテキストを提供してもらい、そこから抽出しています。

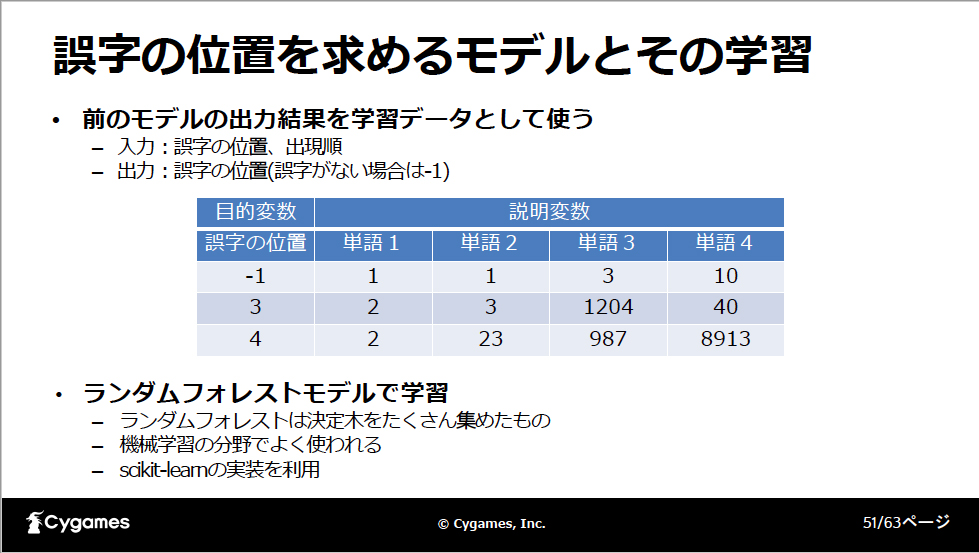
元の文章と誤字を入れた文章を先ほど学習したモデルへ入力して推論を行います。この時出力されるのは、単語ごとの出現順のリストです。この値を次のモデルの学習データとして使います。この時誤字を入れた位置を目的変数として追加しておきます。誤字がない文章の場合は「-1」を入れます。
最後は、誤字の位置を求めるモデルです。前のモデルから出力された単語の出現順の並びから最終的な誤字の位置を決定します。前のモデルから出力された値のうち、誤字の位置が機械学習における目的変数、それ以外の単語の出現順の値が説明変数となります。この2つをセットにした学習データを使って学習を行います。使用するモデルはランダムフォレスト、scikit-learnの実装を使っています。

ただ、こちらの精度は35〜45%程度という結果です。当初は誤字のパターンを少なくしていたので精度が高かったのですが、誤字のパターンを増やしたところ精度が下がってしまいました。誤字の位置を間違って検出してしまうケースが15%程度、残りの50%は誤字があるのに誤字がないと推論してしまうようです。
図で示す例は「イベントは大盛況のちに終わった」という文章の「のち」の部分に誤字があるケースで、これは正しく予測できています。もう1つは、「素敵な歌詞になたと思う」という文章の「なた」の部分に誤字があるのですが、「素敵な」の部分に誤字があると間違えて予測した例です。
ここまでローカルで実装した関数をAWS Lambda上へ持っていきました。Dockerのイメージが大きくなると、Lambdaの更新に時間がかかるため、学習したモデルをDockerイメージにふくめずに別のファイルシステムから読み込む形にしています。
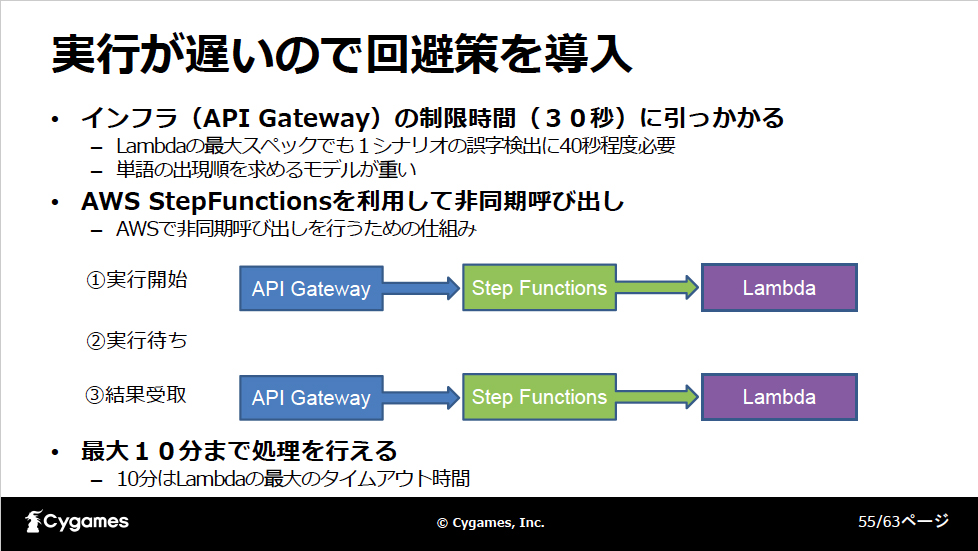
また、Lambdaで実行してみたところインフラ側の制限時間(30秒)に引っかかってしまうことがわかりました。真ん中の単語の出現順を求めるモデルが非常に重く、CPU実行では大半の時間をそこで使ってしまうのです。そこで、AWSのStepFunctionsによる非同期呼び出しの仕組みを追加しました。最初にLambdaで関数の実行を開始し、しばらく経ってから結果を問い合わせて、終わっていれば結果を受け取るという形です。これにより、Lambdaの最大タイムアウト時間の10分まで処理を行えるようになりました。
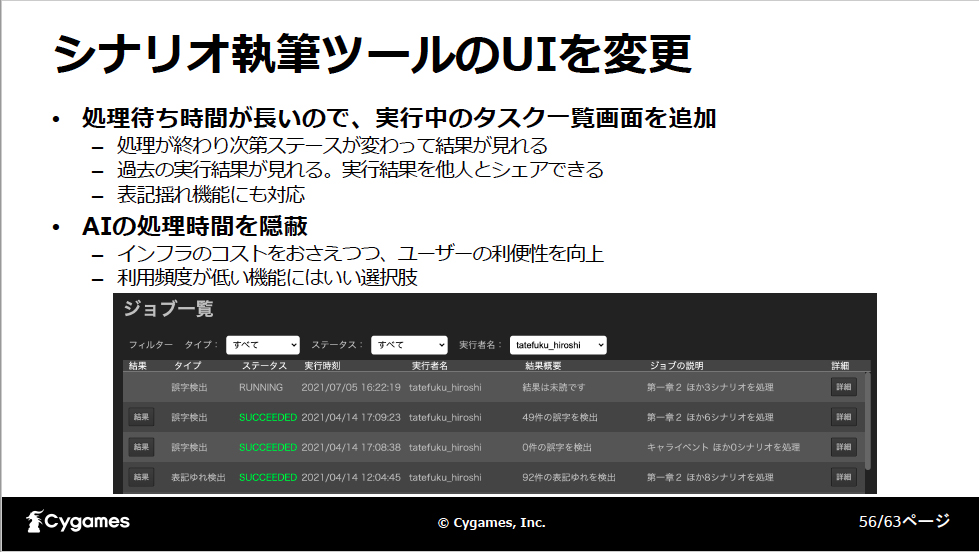
この非同期呼び出しの仕組みに合わせてシナリオ執筆ツールのUIを変更し、処理を開始すると画面をすぐに戻し、実行中の処理は別の画面で見るようにしました。表記揺れも同じ扱いです。このように、UIを工夫することでAIの処理時間を隠蔽することができます。
AIエンジニアがインフラ構築も兼ねる
作業分担は以下のとおりです。画像認識、表記揺れ機能に関しては、AIエンジニア、インフラエンジニア、ツール開発者の3人での作業分担でしたが、誤字検出ではAIエンジニアがインフラ構築も担当する形になっています。これについて立福氏は、機械学習向けのインフラ構築はゲーム運用やWebサービス運用とは勝手が違ってインフラ担当でも実績がないこともあり、AIエンジニアが試行錯誤できるようにインフラ構築まで兼任したほうが話が早い場合もあると分析しています。
画像認識
AIの学習・APIの作成(1人)
– 機械学習モデルの作成(2か月)
– デプロイ(2か月)
AWSのインフラ構築(1人)
– インフラ担当者(1週間)
リソース管理ツールへの機能追加(1人)
– ツールの開発者(1週間)
表記揺れ
機械学習の学習・APIの作成(1人)
– 機能開発(2か月)
– デプロイ(1か月)
AWSのインフラ構築(1人)
– インフラ担当者(2日)
リソース管理ツールへの機能追加(1人)
– ツール開発者(1週間)
誤字検出
機械学習の学習・APIの作成、AWSのインフラ構築(1人)
– 機械学習モデルの作成(4か月)
– インフラ構築(2週間)
– デプロイ(1.5か月)
リソース管理ツールへの機能追加(1人)
– ツール開発者(2週間)
AWS上でInfrastructure as Code(IaC;コードによるインフラ構築運用)を行う「AWS CDK」を使うことで、簡単にインフラ構築が行えたそうです。図のようにAPI Gateway+Lambdaの既存構成にSTEP functionを追加した形になっています。
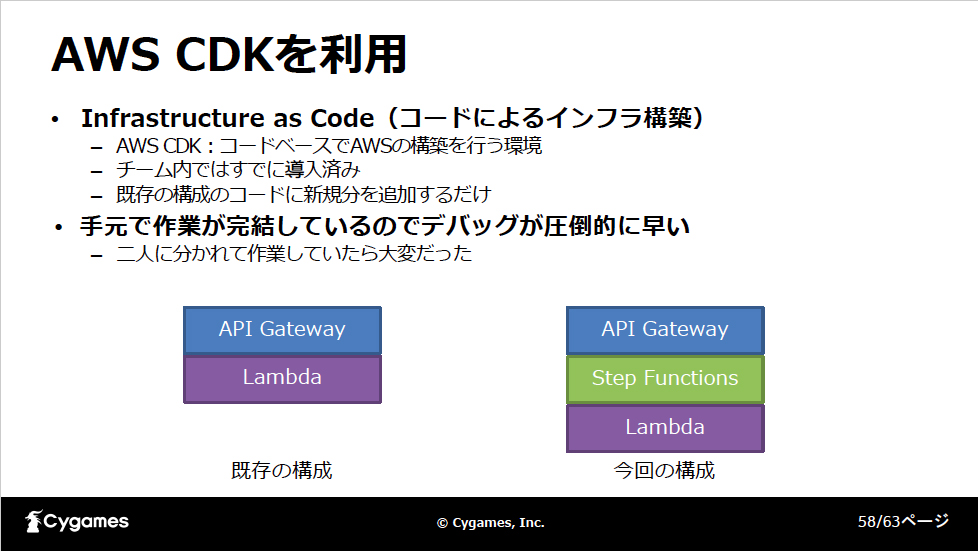
今回の試みの背景には、ゲーム開発におけるAIの導入事例も増え、情報にアクセスしやすくなったことがあります。また、リソース管理ツールやシナリオ執筆ツールのような共通基盤ツールがあると、機械学習の学習データを用意するのが比較的容易になります。このあたりが開発現場にAIを導入する際のポイントになると言えそうです。
Writer:大内孝子



 RANKING
RANKING



