

モリカトロン株式会社運営「エンターテインメント×AI」の最新情報をお届けするサイトです。
- TAG LIST
- CGCGへの扉生成AI安藤幸央吉本幸記月刊エンタメAIニュース河合律子機械学習ディープラーニングOpenAILLM大規模言語モデルGoogleNVIDIA音楽グーグルGANモリカトロン森川幸人ChatGPT三宅陽一郎Stable DiffusionDeepMind強化学習人工知能学会ニューラルネットワークシナリオマイクロソフトQA自然言語処理AIと倫理GPT-3倫理Facebook大内孝子映画SIGGRAPHスクウェア・エニックス著作権アートキャラクターAIルールベースゲームプレイAIMinecraft敵対的生成ネットワークNPC音楽生成AI動画生成AIモリカトロンAIラボインタビューアニメーション3DCG画像生成NFTロボットファッションDALL-E2StyleGANプロシージャルディープフェイクマルチモーダルVFXMidjourney遺伝的アルゴリズムデバッグ自動生成VRメタAIMeta画像生成AIRed RamマンガインタビューゲームAIAdobeMicrosoftテストプレイマインクラフト小説CLIPテキスト画像生成深層学習CEDEC2019toio教育NeRFデジタルツインメタバース不完全情報ゲームStability AIボードゲームDALL-ESoraビヘイビア・ツリーCEDEC2021CEDEC2020作曲アストロノーカロボティクスナビゲーションAI高橋力斗AIアートGeminiメタ畳み込みニューラルネットワークアップルデジタルヒューマンELSIPlayable!スポーツはこだて未来大学エージェントGDC 2021プロンプトGPT-4手塚治虫汎用人工知能JSAI20223D広告DALL-E 3バーチャルヒューマンNVIDIA OmniverseGDC 2019マルチエージェントCEDEC2022市場分析AR懐ゲーから辿るゲームAI技術史鴫原盛之ジェネレーティブAIソニー東京大学栗原聡CNNマーケティングJSAI2024CMBERTMicrosoft Azure音声認識言霊の迷宮UnityOmniverseUbisoftJSAI2023Robloxがんばれ森川君2号電気通信大学SIGGRAPH ASIAHTNApple階層型タスクネットワークAIQVE ONE世界モデルアドベンチャーゲームインディーゲームJSAI2020GTC2023音声合成メタデータTensorFlowブロックチェーンイベントレポートキャリア模倣学習対話型エージェントAmazonサイバーエージェントトレーディングカードメディアアートDQNシーマン合成音声SIERunway水野勇太モリカトロン開発者インタビュー宮本茂則アバターブラック・ジャックGenvid TechnologiesガイスターStyleGAN2徳井直生村井源稲葉通将斎藤由多加Open AIベリサーブGTC2022GPT-3.5YouTube音声生成AISFNetflixJSAI2021松木晋祐Bard研究シムシティシムピープルZorkGPT-4oMCS-AI動的連携モデルマーダーミステリーモーションキャプチャーTEZUKA2020CEDEC2023AGIテキスト生成スパーシャルAIElectronic ArtsGDC Summerイーロン・マスク論文Stable Diffusion XL森山和道Audio2FaceNVIDIA Rivaeスポーツスタンフォード大学アーケードゲームテニスセガ人狼知能Google I/O類家利直FireflyeSportsBLUE PROTOCOLCEDEC2024aibo大澤博隆SFプロトタイピング銭起揚Runway Gen-3 AlphaチャットボットTikToktext-to-3DDreamFusion自動運転車ワークショップEpic GamesAIロボ「迷キュー」に挑戦AWSAdobe MAXクラウドAlphaZeroPreferred NetworksTransformerGPT-2rinnaAIりんなカメラ環世界中島秀之PaLMGitHub CopilotLLaMA哲学Apple Vision Proハリウッド宮路洋一Whisk理化学研究所Gen-1SIGGRAPH Asia 2024テキスト画像生成AI松尾豊人事データマイニングControlNet現代アートDARPA法律ドローンゲームエンジンUnreal EngineImagen人工生命バイアスサム・アルトマンVeoASBSぱいどんAI美空ひばり手塚眞LoRAデザインGDC 2025バンダイナムコ研究所ELYZANEDO建築ELIZAFSM-DNNMindAgentBIMLEFT 4 DEADくまうた通しプレイソニー・インタラクティブエンタテインメントOpenAI FiveMeshy本間翔太馬淵浩希Cygames岡島学ピクサー九州大学プラチナエッグイーサリアム効果音ボエダ・ゴティエビッグデータ中嶋謙互Amadeus Codeデータ分析自動翻訳MILENVIDIA ACEVeo 3ナラティブNianticOmniverse ReplicatorWCCFレコメンドシステムNVIDIA DRIVE SimWORLD CLUB Champion FootballNVIDIA Isaac SimSakana AI柏田知大軍事田邊雅彦トレカ慶應義塾大学Max CooperGPTDisneyPhotoshopPyTorch京都芸術大学ChatGPT4モンテカルロ木探索JSAI2025ByteDance眞鍋和子バンダイナムコスタジオコミコパヒストリアAI Frog Interactive新清士ラベル付け田中章愛ComfyUI齊藤陽介コナミデジタルエンタテインメント成沢理恵お知らせMagic Leap OneTencentサッカーバスケットボールLINEヤフーSuno AIKaKa CreationVOICEVOXtext-to-imageサルでもわかる人工知能VAETEZUKA2023DOOMリップシンキングRNNGameNGenグランツーリスモ・ソフィーUbisoft La Forgeスーパーマリオブラザーズ社員インタビュー知識表現ウォッチドッグス レギオンVTuberIGDA立教大学秋期GTC2022大阪公立大学HALOフォートナイトKLabどうぶつしょうぎジェイ・コウガミ音楽ストリーミングMIT野々下裕子Movie GenQosmoマシンラーニング5GMuZeroRival Peakpixivオムロン サイニックエックスGPTsセキュリティ対話エンジンポケモン3Dスキャン橋本敦史リトル・コンピュータ・ピープルCodexシーマン人工知能研究所コンピューティショナル・フォトグラフィーゴブレット・ゴブラーズ絵画3D Gaussian SplattingMicrosoft DesignerイラストシミュレーションSoul Machines柿沼太一完全情報ゲームバーチャルキャラクター坂本洋典宮本道人釜屋憲彦LLaMA 2ウェイポイントパス検索Hugging Face対談藤澤仁生物学XRGTC 2022xAI画像認識SiemensストライキStyleCLIPDeNAVoyager長谷洋平GDC 2024クラウドコンピューティングmasumi toyotaIBMぎゅわんぶらあ自己中心派OpenSeaGDC 2022Veo 2ウロチョロスSNSTextWorldEarth-2BingエコロジーMagentaソフトバンクSONYポケットモンスターELYZA PencilScenarioSIGGRAPH2023AIピカソGTC2021AI素材.comCycleGANテンセントAndreessen HorowitzQA Tech NightNetHack下田純也桑野範久キャラクターモーション音源分離NBAフェイクニュースユニバーサルミュージックRPGウィル・ライトWeb3SIGGRAPH 2022レベルデザインDreamerV3SIMAAIボイスアクター南カリフォルニア大学NVIDIA CanvasGDCGPUALifeオルタナティヴ・マシンサウンドスケープLaMDATRPGマジック:ザ・ギャザリングAI Dungeon介護BitSummitGemma 2Cube 3DゼビウスNetEaseInworld AIモリカトロンAIコネクトゲーム背景IEEEPoint-EアパレルClaude不気味の谷ナビゲーションメッシュファインチューニング早稲田大学グランツーリスモ写真高橋ミレイ北野宏明深層強化学習松原仁松井俊浩武田英明フルコトモリカコミックパックマンELYZA DIGESTジョージア工科大学Apple IntelligenceWWDCWWDC 2024西成活裕ハイブリッドアーキテクチャAI野々村真LINE AIトークサジェストApex Legends群衆マネジメントライブポートレイトGTC2025NinjaコンピュータRPGライブビジネスWonder StudioAdobe Max 2023GPT-4-turboFuxi Labアップルタウン物語新型コロナ土木佐藤恵助Naraka:Bladepoint MobileKELDIC周済涛Bing Chat大道麻由バトルロイヤルメロディ言語清田陽司インフラBing Image Creator物語構造分析ビヘイビアツリーゲームTENTUPLAYサイバネティックス慶応義塾大学SoftServeMARVEL Future FightAstro人工知能史Amazon BedrockAssistant with Bard渡邉謙吾ALNAIRタイムラプスEgo4DAI哲学マップThe Arcadeここ掘れ!プッカAMRIバスキア星新一X.AISearch Generative ExperienceBLADE日経イノベーション・ラボStyleGAN-XLX Corp.Dynalang濱田直希GAGA敵対的強化学習StyleGAN3TwitterVLE-CE大柳裕⼠QUEEN階層型強化学習GOSU Data LabGANimatorXホールディングス加納基晴Runway Gen-4WANNGOSU Voice AssistantVoLux-GANMagiAI ActSkyReels竹内将SenpAI.GGProjected GANEU研究開発事例MobalyticsSelf-Distilled StyleGANSDXLArs Electronica赤羽進亮Stable Virtual CameraニューラルレンダリングRTFKTAI規制遊戯王IntangibleAWS SagemakerPLATONIKE欧州委員会UDI(Universal Duel Interface)ブライアン・イーノ映像セリア・ホデント形態素解析frame.ioClone X欧州議会第一工科大学EnoUXAWS LambdaFoodly村上隆欧州理事会佐竹空良Brain One誤字検出MusicLM小林篤史AlphaEvolve認知科学中川友紀子Digital MarkAudioLMContinuous Thought Machine(CTM)ゲームデザインSentencePieceアールティSnapchatMusicCaps荻野宏実ArmLUMINOUS ENGINEクリエイターコミュニティAudioCraft伊藤黎Stable Audio Open SmallLuminous ProductionsBlenderBot 3バーチャルペットビヘイビアブランチWord2Worldパターン・ランゲージ竹村也哉Meta AINVIDIA NeMo ServiceMubertWPPSTORY2GAMEちょまどマーク・ザッカーバーグヴァネッサ・ローザMubert RenderGeneral Computer Control(GCC)ウィットウォーターランド大学GOAPWACULVanessa A RosaGen-2Cradle森川の頭の中Adobe MAX 2021陶芸Runway AI Film FestivalSpiral.AI花森リドPlay.htPreVizItakoLLM-7bGoogle I/O 2025音声AI静岡大学AIライティングLiDARCharacter-LLM明治大学FlowOmniverse AvatarAIのべりすとPolycam復旦大学北原鉄朗Lyra 2FPSQuillBotdeforumChat-Haruhi-Suzumiya中村栄太MusicFX DJマルコフ決定過程NVIDIA MegatronCopysmith涼宮ハルヒ日本大学Animon.aiNVIDIA MerlinJasperハーベストEmu VideoヤマハツインズひなひまNVIDIA MetropolisForGames前澤陽Mayaパラメータ設計ゲームマーケットペリドット増田聡Deep Q-Learningバランス調整岡野翔太Dream Track採用AlphaGO協調フィルタリング郡山喜彦Music AI Toolsスペースインベーダーテキサス大学ジェフリー・ヒントンLyria科学史プリンス・オブ・ペルシャGoogle I/O 2023Yahoo!知恵袋AIサイエンティストドラゴンクエストIVAlphaDogfight TrialsAI Messenger VoicebotインタラクティブプロンプトAITerra堀井雄二エージェントシミュレーションOpenAI Codex武蔵野美術大学AI Overview山名学StarCraft IIHyperStyleBingAI石渡正人電通タイトーFuture of Life InstituteRendering with Style手塚プロダクションAICO2カプコンIntel林海象BitSummit DriftUbi AnvilエンジンLAIKADisneyリサーチヴィトゲンシュタイン古川善規V1 Video ModelRotomationGauGAN論理哲学論考Lightroom大規模再構成モデルOmega CrafterArtificial AnalysisGauGAN2CanvaLRMSPACE INVADIANSVideo Arenaドラゴンクエストライバルズ画像言語表現モデルObjaverse西島大介Video Model Leaderboard不確定ゲームSIGGRAPH ASIA 2021PromptBaseBOOTHMVImgNet吉田伸一郎Claude 3.5Dota 2ディズニーリサーチpixivFANBOXOne-2-3-45SIGGRAPH2024MistralMitsuba2バンダイナムコネクサス虎の穴3DガウシアンスプラッティングMotion-I2VソーシャルゲームEmbeddingワイツマン科学研究所ユーザーレビューFantiaワンショット3D生成技術樋口恭介GTC2020CG衣装mimicとらのあなToonify3DClaude 4NVIDIA MAXINEVRファッションBaidu集英社FGDC生成対向ネットワーク小川 昴淡路滋ビデオ会議ArtflowERNIE-ViLG少年ジャンプ+Future Game Development Conference拡散モデルホラーゲームグリムノーツEponym古文書ComicCopilot佐々木瞬DiffusionStable Diffusion 1.5ゴティエ・ボエダ音声クローニング凸版印刷階層型物語構造Gautier Boeda階層的クラスタリングGopherAI-OCRゲームマスターうめ夏目漱石画像判定Inowrld AI小沢高広漱石書簡Julius鑑定MODAniqueドリコム京都情報大学院大学TPRGOxia PalusGhostwriter中村太一ai and上野未貴バーチャル・ヒューマン・エージェントtoio SDK for UnityArt RecognitionSkyrimエグゼリオSaaSクーガー実況パワフルサッカースカイリムCopilotインサイト石井敦NHC 2021桃太郎電鉄RPGツクールMZカスタマーサポート茂谷保伯池田利夫桃鉄ChatGPT_APIMZserial experiments lainComfyUI-AdvancedLivePortraitGDMC新刊案内パワサカダンジョンズ&ドラゴンズAI lainGUIマーベル・シネマティック・ユニバースOracle RPGPCGMITメディアラボMCU岩倉宏介深津貴之PCGRLアベンジャーズPPOxVASynthDungeons&DragonsVideo to Videoマジック・リープDigital DomainMachine Learning Project CanvasLaser-NVビートルズiPhone 16MagendaMasquerade2.0国立情報学研究所ザ・ビートルズ: Get BackOpenAI o1ノンファンジブルトークンDDSPフェイシャルキャプチャー石川冬樹MERFDemucsAIスマートリンクスパコンAlibaba音楽編集ソフトシャープ里井大輝KaggleスーパーコンピュータVQRFAdobe Auditionウェアラブル山田暉松岡 聡nvdiffreciZotopeCE-LLMAssassin’s Creed OriginsAI会話ジェネレーターTSUBAME 1.0NeRFMeshingRX10Communication Edge-LLMSea of ThievesTSUBAME 2.0LERFMoisesGEMS COMPANYmonoAI technologyLSTMABCIマスタリングAIペットモリカトロンAIソリューション富岳レベルファイブYahoo!ニュース初音ミクOculusコード生成AISociety 5.0リアム・ギャラガーAI Comic Factory転移学習テストAlphaCode夏の電脳甲子園グライムスAI comic GeneratorBaldur's Gate 3Codeforces座談会BoomyComicsMaker.aiCandy Crush Saga自己増強型AIジョン・レジェンドGenie AILlamaGen.aiSIGGRAPH ASIA 2020COLMAPザ・ウィークエンドSIGGRAPH Asia 2023GAZAIADOPNVIDIA GET3DドレイクC·ASEFlame PlannerデバッギングBigGANGANverse3DFLARE動画ゲーム生成モデルMaterialGANダンスグランツーリスモSPORTAI絵師エッジワークスMagicAnimateReBeLUGC日本音楽作家団体協議会Animate AnyoneVirtuals ProtocolGTソフィーPGCFCAインテリジェントコンピュータ研究所VolvoFIAグランツーリスモチャンピオンシップVoiceboxアリババMarioVGGNovelAIさくらインターネットDreaMovingRival PrakDGX A100NovelAI DiffusionVISCUIT松原卓二ぷよぷよScratchArt Transfer 2ユービーアイソフトWebcam VTuberモーションデータスクラッチArt Selfie 2星新一賞ビスケットMusical Canvas北尾まどかポーズ推定TCGプログラミング教育The Forever Labyrinth将棋メタルギアソリッドVメッシュ生成Refik AnadolFSMメルセデス・ベンツQRコードVALL-EAlexander RebenMagic Leap囲碁Deepdub.aiRhizomatiksナップサック問題Live NationEpyllionデンソーAUDIOGENMolmo汎用言語モデルWeb3.0マシュー・ボールデンソーウェーブEvoke MusicPixMoAIOpsムーアの法則原昌宏AutoFoleyQwen2 72BSpotifyスマートコントラクト日本機械学会Colourlab.AiDepth ProReplica Studioロボティクス・メカトロニクス講演会ディズニーamuseChitrakarAdobe MAX 2022トヨタ自動車Largo.aiVARIETAS巡回セールスマン問題かんばん方式CinelyticAI面接官ジョルダン曲線メディアAdobe ResearchTaskadeキリンホールディングス政治Galacticaプロット生成Pika.art空間コンピューティングクラウドゲーミングAI Filmmaking AssistantDream Screen和田洋一リアリティ番組映像解析FastGANSynthIDStadiaジョンソン裕子4コママンガAI ScreenwriterFirefly Video ModelMILEsNightCafe東芝デジタルソリューションズ芥川賞Stable Video 4Dインタラクティブ・ストリーミングLuis RuizSATLYS 映像解析AI文学AI受託開発事例インタラクティブ・メディア恋愛田中志弥PFN 3D ScanElevenLabsタップルPlayable!3D東京工業大学HeyGenAbema TVPlayable!MobileLudo博報堂After EffectsNECAdobe MAX 2024ラップPFN 4D Scan絵本木村屋SneaksSIGGRAPH 2019ArtEmisZ世代DreamUp出版GPT StoreIllustratorAIラッパーシステムDeviantArtAmmaar Reshi生成AIチェッカーMeta Quest 3Waifu DiffusionStoriesユーザーローカルXR-ObjectsGROVERプラスリンクス ~キミと繋がる想い~元素法典StoryBird九段理江PeridotFAIRSTCNovel AIVersed東京都同情塔Orionチート検出Style Transfer ConversationProlificDreamer防犯オンラインカジノRCPUnity Sentis4Dオブジェクト生成モデルO2RealFlowRinna Character PlatformUnity MuseAlign Your GaussiansScam DetectioniPhoneCALACaleb WardAYGLive Threat DetectionDeep Fluids宮田龍MAV3D乗換NAVITIMEMeInGameAmelia清河幸子ファーウェイKaedimAIGraphブレイン・コンピュータ・インタフェース西中美和4D Gaussian Splatting3DFY.aiBCIGateboxアフォーダンス安野貴博4D-GSLuma AILearning from VideoANIMAKPaLM-SayCan斧田小夜GlazeAvaturn予期知能逢妻ヒカリWebGlazeBestatセコムNightShadeOasisユクスキュルバーチャル警備システムCode as PoliciesSpawningDecartカント損保ジャパンCaPHave I Been Trained?Dejaboom!CM3leonFortniteUnbounded上原利之Stable DoodleUnreal Editor For FortniteEtchedドラゴンクエストエージェントアーキテクチャアッパーグラウンドコリジョンチェックT2I-Adapter声優PAIROCTOPATH TRAVELERパブリシティ権西木康智Volumetrics日本俳優連合OCTOPATH TRAVELER 大陸の覇者山口情報芸術センター[YCAM]AIワールドジェネレーター日本芸能マネージメント事業者協会アルスエレクトロニカ2019品質保証YCAM日本マネジメント総合研究所Rosebud AI Gamemaker日本声優事業社協議会StyleRigAutodeskアンラーニング・ランゲージLayerIAPP逆転オセロニアBentley Systemsカイル・マクドナルドLily Hughes-RobinsonCharisma.aiTripo 2.0ワールドシミュレーターローレン・リー・マッカーシーColossal Cave AdventureMeta 3D Gen奥村エルネスト純いただきストリートH100鎖国[Walled Garden]プロジェクトAdventureGPT調査スマートシティ齋藤精一大森田不可止COBOLSIGGRAPH ASIA 2022リリー・ヒューズ=ロビンソンMeta Quest都市計画高橋智隆DGX H100VToonifyBabyAGIIP松本雄太ロボユニザナックDGX SuperPODControlVAEGPT-3.5 Turbo早瀬悠真泉幸典仁井谷正充変分オートエンコーダーカーリング強いAIGenie 2ロボコレ2019Instant NeRFフォトグラメトリウィンブルドン弱いAIWorld Labsartonomous回帰型ニューラルネットワークCybeverbitGANsDeepJoin戦術分析Third Dimension AIAzure Machine LearningAzure OpenAI Serviceパフォーマンス測定Lumiere東北大学意思決定モデル脱出ゲームDeepLIoTUNetGemini 2.0Hybrid Reward Architectureコミュニティ管理DeepL WriteProFitXImageFXSuper PhoenixWatsonxMusicFXProject MalmoオンラインゲームAthleticaTextFXフロンティアワークス気候変動コーチング機械翻訳Project Paidiaシンギュラリティ北見工業大学KeyframerSimplifiedProject Lookoutマックス・プランク気象研究所レイ・カーツワイル北見カーリングホールAI Voice over GeneratorWatch Forビョルン・スティーブンスヴァーナー・ヴィンジ画像解析Gemini 1.5AI Audio Enhancer気象モデルRunway ResearchじりつくんAI StudioエーアイLEFT ALIVE気象シミュレーションMake-A-VideoNTT SportictVertex AIAITalk長谷川誠ジミ・ヘンドリックス環境問題PhenakiAIカメラChat with RTXコエステーションBaby Xカート・コバーンDreamixSTADIUM TUBESlackロバート・ダウニー・Jr.エイミー・ワインハウスSDGsText-to-ImageモデルPixelllot S3Slack AIPlayStationPokémon Battle Scopeダフト・パンクメモリスタAIスマートコーチVRMLGlenn MarshallkanaeruTechno MagicThe Age of A.I.Story2Hallucination音声変換Latitude占いゴーストバスターズレコメンデーションJukeboxDreambooth行動ロジック生成AIスパイダーマンVeap Japanヤン・ルカンConvaiポリフォニー・デジタルEAPneoAIPerfusionNTTドコモ荒牧伸志SIFT福井千春DreamIconニューラル物理学EmemeProject SidDCGAN医療mign毛髪GenieAlteraMOBADANNCEメンタルケアstudiffuse荒牧英治汎用AIエージェントRobert Yangハーバード大学Edgar Handy中ザワヒデキAIファッションウィークRazer研修デューク大学大屋雄裕インフルエンサーProject AVA中川裕志Grok-1Streamlabsmynet.aiローグライクゲームAdreeseen HorowitzMixture-of-ExpertsIntelligent Streaming Assistant東京理科大学NVIDIA Avatar Cloud EngineMoEProject DIGITS人工音声NeurIPS 2021産業技術総合研究所Replica StudiosClaude 3スーパーコンピューターリザバーコンピューティングSmart NPCsClaude 3 Haikuエージェンテックプレイ動画ヒップホップ対話型AIモデルRoblox StudioClaude 3 SonnetAI Shorts詩ソニーマーケティングPromethean AIClaude 3 Opusテルアビブ大学サイレント映画もじぱnote森永乳業DiffUHaul環境音暗号通貨note AIアシスタントMusiioC2PATrailBlazerFUZZLEKetchupEndelゲーミフィケーションヴィクトリア大学ウェリントンAlterationAI NewsTomo Kiharazeroscope粒子群最適化法Art SelfiePlayfoolQNeRF進化差分法オープンワールドArt TransferSonar遊びカーネギーメロン大学群知能下川大樹AIFAPet PortraitsSonar+DtsukurunRALF高津芳希P2EBlob Opera地方創生グラフィック大石真史クリムトDolby Atmos吉田直樹メイクBEiTStyleGAN-NADASonar Music Festival素材CanvasDETRライゾマティクスProjectsSporeクリティックネットワーク真鍋大度OpenAI JapanDeepSeekデノイズUnity for Industryアクターネットワーク花井裕也Voice EngineDeepSeek-R1画像処理DMLabRitchie HawtinCommand R+SentropyGLIDEControl SuiteErica SynthOracle Cloud InfrastructureLoopyCPUDiscordAvatarCLIPAtari 100kUfuk Barış MutluGoogle WorkspaceリップシンクSynthetic DataAtari 200MJapanese InstructBLIP AlphaUdioCyberHostCALMYann LeCun日本新聞協会立命館大学OmniHuman-1プログラミング鈴木雅大AIいらすとや京都精華大学CSAMソースコード生成コンセプトアートAI PicassoTacticAIImagen 3GMAIシチズンデベロッパーSonanticColie WertzEmposyNPMPGoogle LabsGitHubCohereリドリー・スコットAIタレントFOOHMicrosoft MuseウィザードリィMCN-AI連携モデル絵コンテAIタレントエージェンシーゲーム生成モデルUrzas.aiストーリーボードmodi.aiProject AstraWHAMデモンストレーター大阪大学Google I/O 2024ChatGPT Edu西川善司並木幸介KikiBlenderBitSummit Let’s Go!!滋賀大学サムライスピリッツ森寅嘉Zoetic AISIGGRAPH 2021ペット感情認識キリンビールストリートファイター半導体Digital Dream LabsPaLM APIデジタルレプリカ音声加工桜AIカメラTopaz Video Enhance AICozmoMakerSuiteGOT7マルタ大学Solist-AIDLSSタカラトミーSkebsynthesia田中達大ローム山野辺一記LOVOTDreambooth-Stable-DiffusionHumanRF大里飛鳥DynamixyzMOFLINActors-HQMove AIベンチマークRomiGoogle EarthSAG-AFTRAICRA2024FactorioU-NetミクシィGEPPETTO AIWGAHao AI Lab13フェイズ構造ユニロボットStable Diffusion web UIチャーリー・ブルッカー大規模基盤モデルカリフォルニア大学ADVユニボToroboGamingAgentXLandGato岡野原大輔東京ロボティクスAI model自己教師あり学習インピーダンス制御AnthropicDEATH STRANDINGAI ModelsIn-Context Learning(ICL)深層予測学習Claude 3.7 SonnetEric Johnson汎用強化学習AIZMO.AI日立製作所Factorio Learning EnvironmentMOBBY’SFLEOculus Questコジマプロダクションロンドン芸術大学モビーディック尾形哲也Deepseek-v3生体情報デシマエンジンGoogle Brainダイビング量子コンピュータAIRECGemini-2-FlashSound Controlアウトドアqubit汎用ロボットLlama-3.3-70BSYNTH SUPERAIスキャニングIBM Quantum System 2オムロンサイニックエックスGPT-4o-Mini照明Maxim PeterKarl Sims自動採寸ViLaInJoshua RomoffArtnome3DLOOKダリオ・ヒルPDDLZOZO NEXTハイパースケープICONATESizerジェン・スン・フアンニューサウスウェールズ大学ZOZO山崎陽斗ワコールHuggingFaceClaude SammutFashion Intelligence System立木創太スニーカーStable Audioオックスフォード大学Partial Visual-Semantic Embedding浜中雅俊UNSTREET宗教Lars KunzeWEARミライ小町Newelse仏教杉浦孔明GPT-4Vテスラ福井健策CheckGoodsコカ・コーラ田向権ソイル大学GameGAN二次流通食品VASA-1Tesla Bot中古市場Coca‑Cola Y3000 Zero SugarVoxCeleb2AIパズルジェネレーターTesla AI DayWikipediaDupe KillerCopilot Copyright CommitmentAniTalkerDolphinGemmaソサエティ5.0Sphere偽ブランドテラバース上海大学SIGGRAPH 2020バズグラフXaver 1000配信京都大学Wild Dolphin Projectニュースタンテキ養蜂立福寛SoundStreamトークナイザー東芝Beewiseソニー・ピクチャーズ アニメーション音声解析音声処理技術DIB-R倉田宜典フィンテック感情分析LumaGPT-4.1投資Fosters+Partners周 済涛Dream MachineGPT-4.1 mini韻律射影MILIZEZaha Hadid ArchitectsステートマシンNTTGPT-4.1 nano韻律転移三菱UFJ信託銀行ディープニューラルネットワークPerplexityLINE AI
【GDCSummer】多様なプレイスタイルを学習し、FPSを人間のようにテストプレイするAIの育て方
2020.9.23ゲーム
ゲーム開発にはテストプレイとバランス調整が欠かせません。近年、多くの企業が人工知能を用いたテストプレイの自動化を検証していますが、ゲームの複雑さや開発規模が増すにつれてスケーラビリティには限界が生じます。また、特定の行動を重視したゲームプレイをAIにテストさせるのは、決して容易ではありません。製品の品質管理をAIが担うためには、ゲーム内で人間のように振る舞えるエージェントが必要不可欠なのです。
8月4日から8月6日までオンライン開催されたGDC Summerにて、Electronic ArtsのAI研究者Igor Borovikov氏による、「Imitation Learning: Building Practical Agents to Test and Explore a First-Person Shooter」(模倣学習:FPSのテストプレイに役立つエージェントの構築)というセッションを取材しました。
このセッションでは、開発途中のFPSタイトルをAIにテストプレイさせることを想定して、攻撃重視やステルス重視といったプレイスタイルの導入を、強化学習と模倣学習による手法で技術検証しています。
強化学習と模倣学習を組み合わせたアプローチ
ビデオゲームにおけるキャラクターの意思決定は、強化学習におけるマルコフ決定過程で定式化できます。マルコフ決定過程は、状態遷移が確率的に生じる動的システムにおける確率モデルであり、遷移後の状態と報酬は直前の状態と行動のみに依存します。すなわち、エージェントが行動を選択するたびに環境は確率的に状態遷移し、その都度エージェントは環境から確率的に報酬を得ます。これらの確率を決定するのが、マルコフ決定過程です。
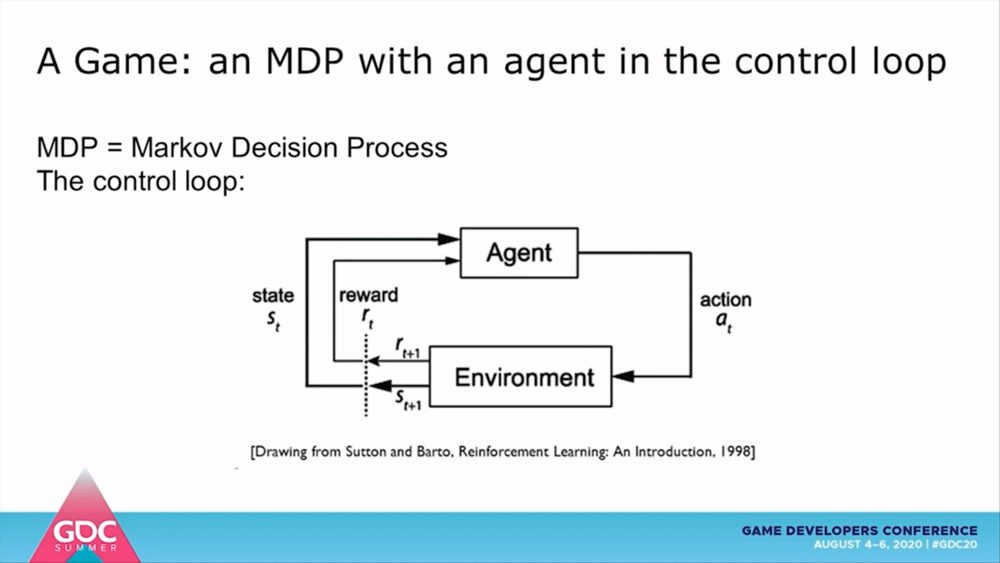
しかし、強化学習だけでは人間のように振る舞う自動プレイエージェントは実現できません。ゲーム開発の現場では、高速で反復できる処理能力が求められます。ビルドが変わるたびに数日から数週間を学習に費やしていては使い物になりません。また、学習の計算コストにも現実的な数字が求められます。何よりも、強化学習にプレイスタイルという制約を組み込むには、かなり繊細な報酬設計が必要になるため一筋縄では行きません。
一方で、模倣学習にもいくつかの課題があります。まず、仕様変更のたびにデモンストレーションを作り直さなければならないため、どうしてもリソースコストが大幅に増加してしまいます。また、ゲームプレイにおけるすべての性質をカバーできるとは限りません。くわえて、人間のデモンストレーションを模倣したエージェントに人間より優れたパフォーマンスを期待することはできません。
そこで今回の検証では、後述するマルコフアンサンブルによりデモンストレーションからベースモデルを構築し、観測不可能な状態における未定義の行動はヒューリスティクスを介して指定。マルコフアンサンブルとヒューリスティクスの統合モデルを使ってエージェントにゲームプレイを学習させるというアプローチが取られています。これをディープニューラルネットワークやビヘイビア・ツリーを用いて最適化することで実用化を目指します。
多様なプレイスタイルをいかに学習させるか
一般的なFPSタイトルでは、「前方に走る」「伏せる」「身を隠す」のような一連の行動が、キャラクターの状態やプレイスタイルに応じた確率で、「回復アイテムを使う」「武器を変える」「休む」といった異なる次の行動につながります。この時、それぞれの確率を決定して、次の行動を予想するためにマルコフモデルが使われます。

マルコフモデルは単一の行動に対しては効果的ですが、現実には多様な状態に対応しなければならず、そのすべてが観測できるとは限りません。また、デモンストレーションではカバーしきれていない行動もあるかもしれません。こうした課題を解決するために、検証ではスタイルを決定するNグラム、記録された状態の量子化、デモンストレーションの順序という3次元のアンサンブルモデルを構築しています。
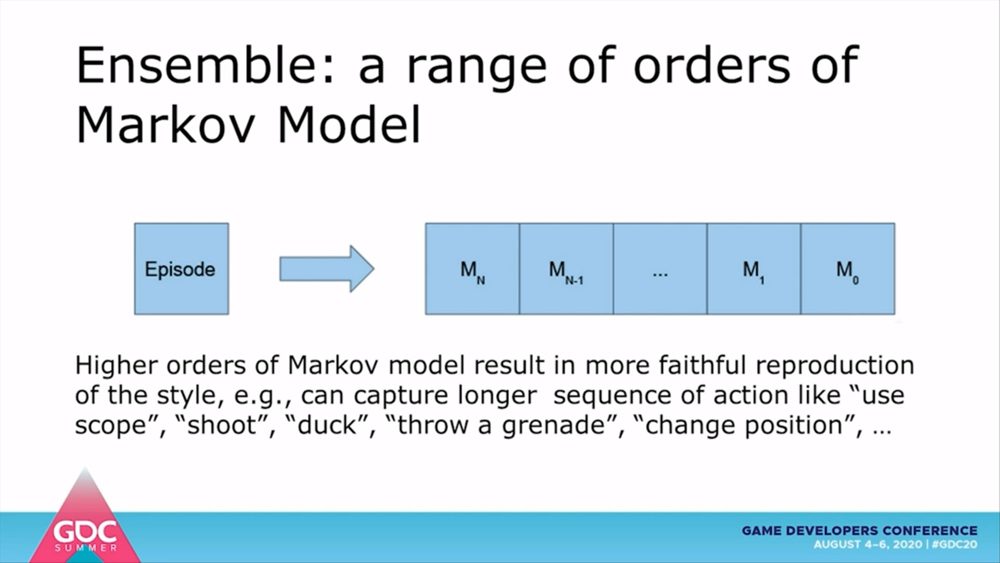
デモンストレーションとなるエピソードは、記録されたNグラムの状態と行動の連続で構成されています。それぞれのマルコフモデルが各状態における遷移確率を定義します。ここでは、マルコフモデルのNグラムが高順位になるほど、特定のプレイスタイルをより忠実に実行できることを示しています。たとえば、「スコープを覗く」「撃つ」「伏せる」「グレネードを投げる」「位置を変える」といった一連の動作を正確に実行できるわけです。

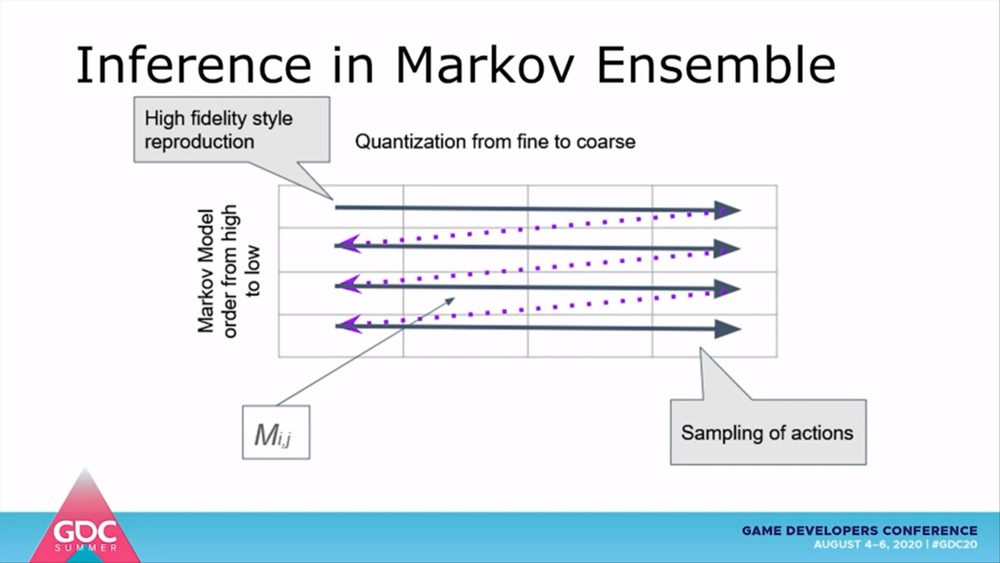
前述した量子化とは、連続的な変数を離散化することを指します。信号処理や画像処理においては、信号の大きさを離散的な値で近似的に表す際に使われます。FPSではキャラクターの速度やターゲットまでの距離が連続的な変数に該当します。そこで距離という連続的な変数を、「遠すぎて何もできない」「スナイパーライフルが使える」「近接武器が使える」といった具合に離散的な値に変換する必要があるのです。なお、どの程度もとの状態に近似しているかは、量子化の閾値によって定義します。

すべての順位と量子化におけるマルコフモデルを組み合わせることで、2次元のマトリクスが形成されます。マトリクスの縦軸はマルコフモデルの順位、横軸は量子化の閾値を示しており、一番左上がもっとも忠実度が高いマルコフモデルとなります。ここにデモンストレーションを時系列順に指定することで、3次元からなるマルコフアンサンブルが構築されます。なお、エージェントの学習途中でプレイヤーに操作権限を移行すれば、デモンストレーションを修正しながらインタラクティブに学習させることも可能だということです。
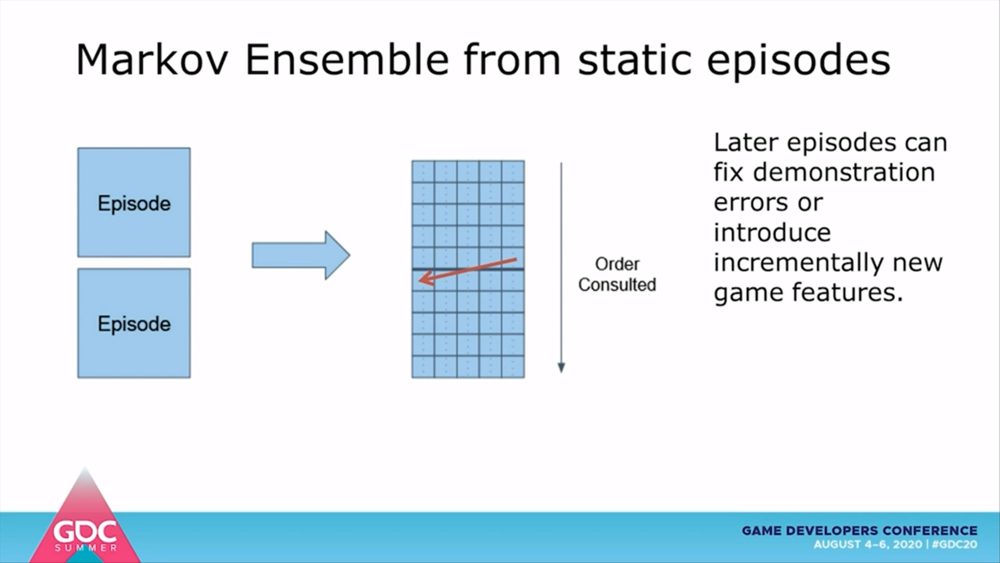
このセッションでは、流し台の中をスプーンが移動しながら家庭用品と戦うというシンプルなゲームを用いて、マルコフアンサンブルにおけるエージェントの学習が検証されました。スプーンが他の家庭用品に接触すると戦闘状態になり、食べ物に接触すると消費して体力を回復できるという最低限のメカニクスのみが実装されています。それぞれのマルコフモデルは10秒間隔で更新されます。このサンプルはFPSではないものの、マルコフモデルにおけるエージェントの挙動を描写するには十分な役割を果たしています。

人間のような振る舞いをどう定義するか
人間とAIを隔てる大きな溝のひとつに、ゲームジャンルに応じた直感的な知識があります。例えば、人間がアクションゲームをプレイする際、破壊したり飛び越えたりできない壁に延々とぶつかり続けるといった支離滅裂な行動は取りません。このように人間は可視化された情報をもとに直感的な判断を下せるため、人間によるデモンストレーションは不完全だといえます。このデモンストレーションからAIが人間のように目標や報酬を推定することは至難の業です。そこで避けて通れないのが知識工学です。
観測不可能な状態における未定義の行動をヒューリスティクスで指定する例として、残り体力や残弾数をもとにウェイポイントを選択するという手法が挙げられます。例えば、デス数に対するキル数の比率を最大化したい場合、残り体力と残弾数が多い時は敵をウェイポイントに設定し、反対に瀕死状態の時は回復アイテムをウェイポイントに設定することで、エージェントは生存率を維持しつつもアグレッシブな行動を選択するようになります。
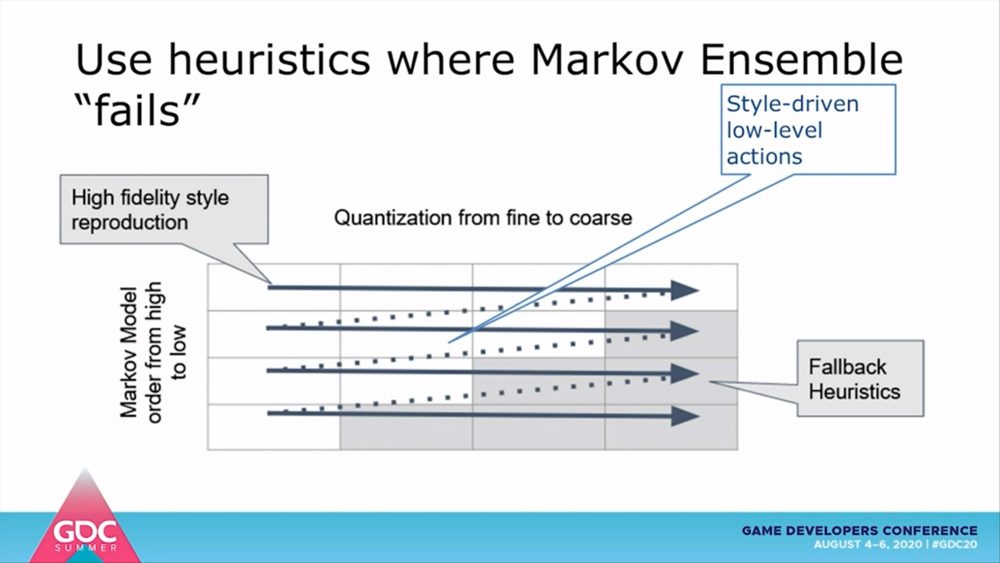
このように、マルコフアンサンブルによって定義されたスタイルだけでは通用しない状態においては、知識工学に基づいたヒューリスティクスが非常に役立ちます。これがマルコフアンサンブルとヒューリスティクスの統合モデルです。残された課題は、線形的に増加していく計算コストを最適化する方法です。
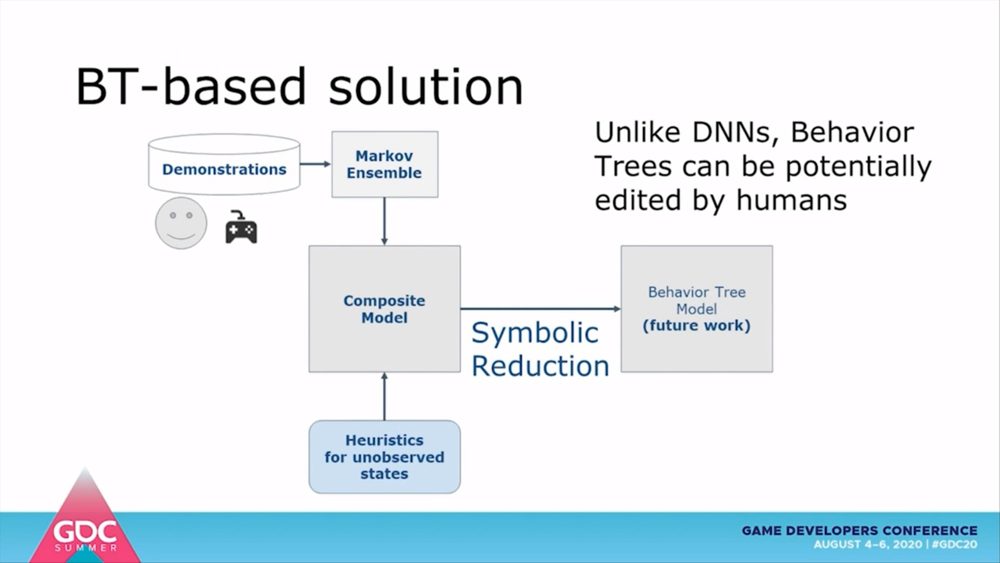
これには、マルコフアンサンブルとヒューリスティクスを統合するためのディープニューラルネットワーク(DNN)を構築する手法と、デモンストレーションのデータをビヘイビア・ツリーへ圧縮変換する手法があります。後者はDNNと異なり、人間によって改変できるという利点があります。また、データ構造がもともとツリーの性質を持っていることも有利な点といえるでしょう。実際の変換プロセスは、今後の研究課題だということでした。
Writer:Ritsuko Kawai / 河合律子



 RANKING
RANKING



