

モリカトロン株式会社運営「エンターテインメント×AI」の最新情報をお届けするサイトです。
- TAG LIST
- CGCGへの扉生成AI吉本幸記安藤幸央月刊エンタメAIニュース河合律子LLMOpenAI大規模言語モデル機械学習ディープラーニンググーグルGoogle音楽NVIDIAモリカトロンChatGPT森川幸人GAN三宅陽一郎DeepMind強化学習Stable Diffusion人工知能学会シナリオニューラルネットワークQAマイクロソフト倫理自然言語処理SIGGRAPHAIと倫理GPT-3映画スクウェア・エニックス大内孝子アートFacebook音楽生成AIルールベース著作権3DCG動画生成AIキャラクターAINPCデバッグ敵対的生成ネットワークアニメーションロボットゲームプレイAIMinecraftモリカトロンAIラボインタビュープロシージャルディープフェイクNFT画像生成VFXファッションStyleGANDALL-E2マルチモーダルRed RamGeminiAdobe遺伝的アルゴリズムメタAI教育自動生成テストプレイMidjourneyVR小説ボードゲームマンガMetaStability AI画像生成AIGPT-4oインタビューゲームAI不完全情報ゲーム深層学習CEDEC2019toioMicrosoftマインクラフトCLIPテキスト画像生成Playable!NeRFSoraビヘイビア・ツリー広告DALL-ECEDEC2021バーチャルヒューマンデジタルツインメタバースELSI高橋力斗作曲アストロノーカロボティクスナビゲーションAI畳み込みニューラルネットワークARアップルSIGGRAPH ASIAスポーツ手塚治虫汎用人工知能3DCEDEC2020AIアートはこだて未来大学エージェントGDC 2021アドベンチャーゲームメタ市場分析デジタルヒューマン東京大学JSAI2022プロンプトGPT-4CMGDC 2019マルチエージェントHTNソニー栗原聡CNNマーケティング懐ゲーから辿るゲームAI技術史鴫原盛之NVIDIA OmniverseCEDEC2022ジェネレーティブAIDALL-E 3言霊の迷宮ブロックチェーン人狼知能音声認識Ubisoft階層型タスクネットワークYouTubeJSAI2020Microsoft Azure模倣学習Unityインディーゲーム音声合成BERTOmniverseRobloxがんばれ森川君2号NetflixGPT-3.5AIQVE ONE世界モデルGTC2023JSAI2023電気通信大学AppleJSAI2024イベントレポート対話型エージェントシーマン水野勇太ガイスター斎藤由多加SF研究シムシティシムピープルTEZUKA2020スパーシャルAIElectronic ArtsメタデータTensorFlowキャリアAmazonDQNSIEアバターGenvid TechnologiesStyleGAN2JSAI2021ZorkMCS-AI動的連携モデルモーションキャプチャーAGI高橋ミレイCygamesサイバーエージェント合成音声モリカトロン開発者インタビュー宮本茂則チャットボットAWS徳井直生GTC2022Unreal Engineテキスト生成デザイントレーディングカードメディアアートtext-to-imageAdobe MAXOpen AIベリサーブ音声生成AI松木晋祐BardControlNetブラック・ジャック村井源稲葉通将ユニバーサルミュージックマーダーミステリーCEDEC2023LoRAXRVeoRunwayGPT-5Amadeus CodeeSportsお知らせワークショップクラウドAlphaZeroAIりんなカメラ環世界中島秀之宮路洋一理化学研究所テンセント人事DARPAドローン人工生命ASBSぱいどんAI美空ひばり手塚眞GDC Summer岡島学eスポーツスタンフォード大学テニスBLUE PROTOCOLaibo銭起揚自動運転車TransformerGPT-2シミュレーション哲学現代アートバンダイナムコ研究所ELYZANVIDIA RivaEpic GamesrinnaSNS松尾豊データマイニングゲームエンジンImagenバイアスサム・アルトマンNEDO森山和道自動翻訳アーケードゲームセガ類家利直大澤博隆SFプロトタイピングコナミデジタルエンタテインメントtext-to-3DDreamFusionAIロボ「迷キュー」に挑戦Preferred NetworksPaLMGitHub CopilotGen-1大阪大学建築イーロン・マスクStable Diffusion XLAudio2FaceGoogle I/OFireflyTikTok立教大学KLabLLaMAハリウッドテキスト画像生成AI法律論文Niantic新清士Apple Vision ProByteDanceCEDEC2024Runway Gen-3 AlphaスーパーマリオブラザーズWhiskSIGGRAPH Asia 2024DeepSeekGDCモリカトロンAIコネクトClaudeAnthropicGDC 2025モリカコミックVeo 3JSAI2025OpenAI o3CEDEC2025Sora 2OpenAI Fiveピクサービッグデータナラティブエージェントシミュレーション眞鍋和子齊藤陽介成沢理恵Magic Leap Oneサルでもわかる人工知能リップシンキングUbisoft La Forge知識表現IGDAどうぶつしょうぎジェイ・コウガミ音楽ストリーミングマシンラーニング5G対話エンジンシーマン人工知能研究所ゴブレット・ゴブラーズ完全情報ゲームウェイポイントパス検索藤澤仁画像認識DeNA長谷洋平ぎゅわんぶらあ自己中心派ウロチョロスNBAフェイクニュースウィル・ライトレベルデザインGPUALifeオルタナティヴ・マシンサウンドスケープTRPGAI Dungeonゼビウス不気味の谷写真松井俊浩パックマン通しプレイ本間翔太馬淵浩希中嶋謙互FPSレコメンドシステム軍事PyTorchモンテカルロ木探索バンダイナムコスタジオ田中章愛サッカーバスケットボールVAERNNウォッチドッグス レギオンHALOMITMuZeroRival Peakリトル・コンピュータ・ピープルコンピューティショナル・フォトグラフィー絵画坂本洋典釜屋憲彦生物学StyleCLIPmasumi toyotaTextWorldBingMagentaGTC2021CycleGANNetHackAIボイスアクター南カリフォルニア大学NVIDIA CanvasNetEaseナビゲーションメッシュ深層強化学習ELYZA DIGESTELIZALEFT 4 DEADプラチナエッグイーサリアムボエダ・ゴティエOmniverse ReplicatorNVIDIA DRIVE SimNVIDIA Isaac SimDisneyAI会話ジェネレーターグランツーリスモ・ソフィーVTuberフォートナイトQosmoポケモンCodexSoul Machinesバーチャルキャラクター対談GTC 2022SiemensクラウドコンピューティングOpenSeaGDC 2022Earth-2エコロジーELYZA Pencil医療キャラクターモーションRPGSIGGRAPH 2022LaMDAマジック:ザ・ギャザリング介護Romi松原仁武田英明フルコトデータ分析MILEWCCFWORLD CLUB Champion Football柏田知大田邊雅彦トレカMax Cooper京都芸術大学ラベル付け秋期GTC2022野々下裕子pixivセキュリティ3DスキャンMicrosoft Designerイラスト柿沼太一ScenarioAIピカソAI素材.comAndreessen HorowitzQA Tech Night下田純也桑野範久noteDreamerV3Blenderゲーム背景Point-EアパレルBIMGPTPhotoshopChatGPT4コミコパTencentTEZUKA2023大阪公立大学オムロン サイニックエックスFastGAN橋本敦史宮本道人LLaMA 2Hugging FacexAIストライキVoyagerIBMソフトバンクSIGGRAPH2023音源分離Web3BitSummitファインチューニンググランツーリスモ量子コンピュータ北野宏明立福寛FSM-DNNMindAgent効果音NVIDIA ACE慶應義塾大学ヒストリアAI Frog InteractiveComfyUISuno AIKaKa CreationVOICEVOXGPTs3D Gaussian SplattingGDC 2024調査ポケットモンスターインフルエンサーSIMAGemma 2Inworld AIIEEE早稲田大学Apple IntelligenceWWDCWWDC 2024Perplexityくまうた濱田直希ソニー・インタラクティブエンタテインメント遊戯王佐竹空良九州大学伊藤黎Sakana AILINEヤフーDOOMGameNGen社員インタビューMovie GenSynthIDPlayable!MobileSneaksPeridot声優早瀬悠真Veo 2機械翻訳SONYProject SidRazerCube 3DベンチマークHao AI Labジョージア工科大学MeshyFlowGemini 2.5-proGemini 2.5 Flash ImageKeep4oGenie 3Nano BananaEXPO2025大阪・関西万博アトラクチャー中村政義森旭彦Veo 3.1はらぺこミームSIGGRAPH Asia 2025ゲーム映像パラメータ設計バランス調整Dota 2ソーシャルゲーム淡路滋グリムノーツゴティエ・ボエダGautier BoedaJuliusTPRGバーチャル・ヒューマン・エージェントクーガー石井敦茂谷保伯マジック・リープノンファンジブルトークン里井大輝GEMS COMPANY初音ミク転移学習デバッギング北尾まどか将棋ナップサック問題SpotifyReplica Studioamuseクラウドゲーミング和田洋一StadiaSIGGRAPH 2019iPhoneAIGraph予期知能ドラゴンクエストPAIRアルスエレクトロニカ2019逆転オセロニア奥村エルネスト純齋藤精一高橋智隆ロボユニ泉幸典ロボコレ2019意思決定モデルLEFT ALIVE長谷川誠Baby Xロバート・ダウニー・Jr.The Age of A.I.レコメンデーションMOBA研修mynet.ai人工音声プレイ動画群知能Sporeデノイズ画像処理CPUGMAIウィザードリィ西川善司サムライスピリッツストリートファイター山野辺一記大里飛鳥13フェイズ構造Oculus Quest生体情報照明山崎陽斗立木創太GameGANソサエティ5.0SIGGRAPH 2020DIB-RApex LegendsNinjaTENTUPLAYMARVEL Future Fightタイムラプスバスキア階層型強化学習WANN竹内将セリア・ホデントUX認知科学ゲームデザインLUMINOUS ENGINELuminous Productionsパターン・ランゲージちょまどマルコフ決定過程協調フィルタリングAlphaDogfight TrialsStarCraft IIFuture of Life InstituteIntelLAIKARotomationドラゴンクエストライバルズ不確定ゲームEmbeddingGTC2020NVIDIA MAXINEビデオ会議階層的クラスタリングtoio SDK for UnityGDMCMITメディアラボMagendaDDSPKaggleAssassin’s Creed OriginsSea of ThievesmonoAI technologyOculusテストBaldur's Gate 3Candy Crush SagaSIGGRAPH ASIA 2020BigGANMaterialGANReBeLVolvoRival PrakユービーアイソフトメタルギアソリッドVFSM汎用言語モデルChitrakar巡回セールスマン問題ジョルダン曲線リアリティ番組ジョンソン裕子MILEsインタラクティブ・ストリーミングインタラクティブ・メディアLudoArtEmisGROVERFAIRチート検出オンラインカジノRealFlowDeep FluidsMeInGameブレイン・コンピュータ・インタフェースBCILearning from VideoユクスキュルカントエージェントアーキテクチャOCTOPATH TRAVELER西木康智OCTOPATH TRAVELER 大陸の覇者StyleRigいただきストリート大森田不可止ザナック仁井谷正充Azure Machine Learning脱出ゲームHybrid Reward ArchitectureSuper PhoenixProject MalmoProject PaidiaProject LookoutWatch Forジミ・ヘンドリックスカート・コバーンエイミー・ワインハウスダフト・パンクGlenn MarshallStory2HallucinationJukeboxSIFTDCGANDANNCEハーバード大学デューク大学ローグライクゲームNeurIPS 2021ヒップホップ詩サイレント映画環境音粒子群最適化法進化差分法下川大樹高津芳希大石真史BEiTDETRSentropyDiscordCALMプログラミングソースコード生成シチズンデベロッパーGitHubMCN-AI連携モデル並木幸介森寅嘉SIGGRAPH 2021半導体Topaz Video Enhance AIDLSSDynamixyzU-NetADVXLandDEATH STRANDINGEric JohnsonコジマプロダクションデシマエンジンMaxim PeterJoshua Romoffハイパースケープミライ小町テスラTesla BotTesla AI Dayバズグラフニュースタンテキ東芝倉田宜典韻律射影韻律転移コンピュータRPGアップルタウン物語KELDICメロディ言語AstroEgo4D日経イノベーション・ラボ敵対的強化学習GOSU Data LabGOSU Voice AssistantSenpAI.GGMobalyticsAWS Sagemaker形態素解析AWS Lambda誤字検出SentencePiece竹村也哉GOAPAdobe MAX 2021Omniverse AvatarNVIDIA MegatronNVIDIA MerlinNVIDIA Metropolisテキサス大学AI Messenger VoicebotOpenAI CodexHyperStyleRendering with StyleDisneyリサーチGauGANGauGAN2画像言語表現モデルSIGGRAPH ASIA 2021ディズニーリサーチMitsuba2ワイツマン科学研究所CG衣装VRファッションArtflowEponym音声クローニングGopher鑑定Oxia PalusArt RecognitionNHC 2021池田利夫新刊案内マーベル・シネマティック・ユニバースMCUアベンジャーズDigital DomainMasquerade2.0フェイシャルキャプチャー山田暉LSTMモリカトロンAIソリューションコード生成AIAlphaCodeCodeforces自己増強型AICOLMAPADOPGANverse3DグランツーリスモSPORTGTソフィーFIAグランツーリスモチャンピオンシップDGX A100Webcam VTuber星新一賞Live NationWeb3.0AIOpsスマートコントラクトメディア政治NightCafeLuis Ruiz東京工業大学博報堂ラップZ世代AIラッパーシステムプラスリンクス ~キミと繋がる想い~STCStyle Transfer ConversationRCPRinna Character PlatformAmeliaGateboxANIMAK逢妻ヒカリセコムバーチャル警備システム損保ジャパン上原利之アッパーグラウンド品質保証AutodeskBentley SystemsワールドシミュレーターH100COBOLDGX H100DGX SuperPODInstant NeRFartonomousbitGANsコミュニティ管理オンラインゲーム気候変動マックス・プランク気象研究所ビョルン・スティーブンス気象モデル気象シミュレーション環境問題SDGsメモリスタ音声変換Veap JapanEAP福井千春メンタルケアEdgar Handy東京理科大学産業技術総合研究所リザバーコンピューティングソニーマーケティングもじぱ暗号通貨FUZZLEAlterationオープンワールドAIFAP2EStyleGAN-NADAUnity for IndustryGLIDEAvatarCLIPSynthetic DataSonanticCohereUrzas.aiKikiZoetic AIペットDigital Dream LabsCozmoタカラトミーLOVOTMOFLINミクシィユニロボットユニボGato汎用強化学習AIロンドン芸術大学Google BrainSound ControlSYNTH SUPERKarl SimsArtnomeICONATE浜中雅俊福井健策WikipediaSphereXaver 1000養蜂Beewiseフィンテック投資MILIZE三菱UFJ信託銀行西成活裕群衆マネジメントライブビジネス新型コロナ周済涛清田陽司サイバネティックス人工知能史AI哲学マップ星新一StyleGAN-XLStyleGAN3GANimatorVoLux-GANProjected GANSelf-Distilled StyleGANニューラルレンダリングPLATOframe.ioFoodly中川友紀子アールティBlenderBot 3Meta AIマーク・ザッカーバーグWACULAIライティングAIのべりすとQuillBotCopysmithJasperヴィトゲンシュタイン論理哲学論考PromptBaseバンダイナムコネクサスユーザーレビューmimicBaiduERNIE-ViLG古文書凸版印刷AI-OCR画像判定実況パワフルサッカー桃太郎電鉄桃鉄パワサカ岩倉宏介PPOMachine Learning Project Canvas国立情報学研究所石川冬樹スパコンスーパーコンピュータ松岡 聡TSUBAME 1.0TSUBAME 2.0ABCI富岳Society 5.0夏の電脳甲子園座談会NVIDIA GET3DAI絵師UGCPGCNovelAINovelAI Diffusionモーションデータポーズ推定メッシュ生成メルセデス・ベンツMagic LeapEpyllionマシュー・ボールムーアの法則Adobe MAX 2022Adobe ResearchGalactica映像解析東芝デジタルソリューションズSATLYS 映像解析AIPFN 3D ScanPFN 4D ScanDreamUpDeviantArtWaifu Diffusion元素法典Novel AICALAアフォーダンスPaLM-SayCanCode as PoliciesCaPコリジョンチェック山口情報芸術センター[YCAM]YCAMアンラーニング・ランゲージカイル・マクドナルドローレン・リー・マッカーシー鎖国[Walled Garden]プロジェクトSIGGRAPH ASIA 2022VToonifyControlVAE変分オートエンコーダーフォトグラメトリ回帰型ニューラルネットワークDeepJoinAzure OpenAI ServiceDeepLDeepL Writeシンギュラリティレイ・カーツワイルヴァーナー・ヴィンジRunway ResearchMake-A-VideoPhenakiDreamixText-to-ImageモデルLatitudeneoAIDreamIconmignstudiffuse対話型AIモデルnote AIアシスタントKetchupAI NewsArt SelfieArt TransferPet PortraitsBlob OperaクリムトクリティックネットワークアクターネットワークDMLabControl SuiteAtari 100kAtari 200MYann LeCun鈴木雅大コンセプトアートColie Wertzリドリー・スコット絵コンテストーリーボードPaLM APIMakerSuiteSkebDreambooth-Stable-DiffusionGoogle EarthGEPPETTO AIStable Diffusion web UIAI modelAI ModelsZMO.AIMOBBY’SモビーディックダイビングアウトドアAIスキャニング自動採寸3DLOOKSizerワコールスニーカーUNSTREETNewelseCheckGoods二次流通中古市場Dupe Killer偽ブランド配信ソニー・ピクチャーズ アニメーションFosters+PartnersZaha Hadid ArchitectsライブポートレイトWonder Studio土木インフラAmazon BedrockX.AIX Corp.TwitterXホールディングスMagiSDXLRTFKTNIKEClone X村上隆Digital MarkSnapchatクリエイターコミュニティバーチャルペットNVIDIA NeMo Serviceヴァネッサ・ローザVanessa A Rosa陶芸Play.ht音声AILiDARPolycamdeforumハーベストForGamesゲームマーケット岡野翔太郡山喜彦ジェフリー・ヒントンGoogle I/O 2023武蔵野美術大学BingAILightroomCanvaBOOTHpixivFANBOX虎の穴Fantiaとらのあな集英社少年ジャンプ+ComicCopilotゲームマスターInowrld AIMODGhostwriterSkyrimスカイリムRPGツクールMZChatGPT_APIMZダンジョンズ&ドラゴンズOracle RPG深津貴之xVASynthLaser-NVMERFAlibabaVQRFnvdiffrecNeRFMeshingLERFマスタリングリアム・ギャラガーグライムスBoomyジョン・レジェンドザ・ウィークエンドドレイクエッジワークス日本音楽作家団体協議会FCAVoiceboxさくらインターネットぷよぷよTCGQRコード囲碁デンソーデンソーウェーブ原昌宏日本機械学会ロボティクス・メカトロニクス講演会トヨタ自動車かんばん方式プロット生成4コママンガElevenLabsHeyGenAfter Effects絵本出版Ammaar ReshiStoriesStoryBirdVersedProlificDreamerUnity SentisUnity MuseCaleb Ward宮田龍清河幸子西中美和安野貴博斧田小夜CM3leonStable DoodleT2I-Adapter日本マネジメント総合研究所Lily Hughes-RobinsonColossal Cave AdventureAdventureGPTリリー・ヒューズ=ロビンソンBabyAGIGPT-3.5 Turboカーリングウィンブルドン戦術分析パフォーマンス測定IoTProFitXWatsonxAthleticaコーチング北見工業大学北見カーリングホール画像解析じりつくんNTT SportictAIカメラSTADIUM TUBEPixelllot S3AIスマートコーチDreamboothヤン・ルカンPerfusionニューラル物理学毛髪荒牧英治中ザワヒデキ大屋雄裕中川裕志Adreeseen HorowitzNVIDIA Avatar Cloud EngineReplica StudiosSmart NPCsRoblox StudioPromethean AIMusiioEndelSonarSonar+DDolby AtmosSonar Music Festivalライゾマティクス真鍋大度花井裕也Ritchie HawtinErica SynthUfuk Barış MutluJapanese InstructBLIP Alpha日本新聞協会AIいらすとやAI PicassoEmposyAIタレントAIタレントエージェンシーmodi.aiBitSummit Let’s Go!!デジタルレプリカGOT7synthesiaHumanRFActors-HQSAG-AFTRAWGAチャーリー・ブルッカー岡野原大輔自己教師あり学習In-Context Learning(ICL)qubitIBM Quantum System 2ダリオ・ヒルジェン・スン・フアンHuggingFaceStable Audio宗教仏教コカ・コーラ食品Coca‑Cola Y3000 Zero SugarCopilot Copyright Commitmentテラバース京都大学音声解析感情分析周 済涛ステートマシンディープニューラルネットワークハイブリッドアーキテクチャAdobe Max 2023Bing ChatBing Image CreatorAssistant with BardThe ArcadeSearch Generative ExperienceDynalangVLE-CEAI ActEUArs ElectronicaAI規制欧州委員会欧州議会欧州理事会MusicLMAudioLMMusicCapsAudioCraftMubertMubert RenderGen-2Runway AI Film FestivalPreVizCharacter-LLM復旦大学Chat-Haruhi-Suzumiya涼宮ハルヒEmu VideoペリドットDream TrackMusic AI ToolsLyriaYahoo!知恵袋インタラクティブプロンプトAI石渡正人手塚プロダクション林海象古川善規大規模再構成モデルLRMObjaverseMVImgNetOne-2-3-453Dガウシアンスプラッティングワンショット3D生成技術FGDCFuture Game Development Conference佐々木瞬Anique中村太一エグゼリオCopilotserial experiments lainAI lainPCGPCGRLDungeons&Dragonsビートルズザ・ビートルズ: Get BackDemucs音楽編集ソフトAdobe AuditioniZotopeRX10MoisesレベルファイブGenie AISIGGRAPH Asia 2023C·ASEFLAREダンスMagicAnimateAnimate Anyoneインテリジェントコンピュータ研究所アリババDreaMovingVISCUITScratchスクラッチビスケットプログラミング教育VALL-EDeepdub.aiAUDIOGENEvoke MusicAutoFoleyColourlab.AiディズニーLargo.aiCinelyticTaskadePika.artAI Filmmaking AssistantAI Screenwriter芥川賞文学恋愛タップルAbema TVNEC木村屋GPT Store生成AIチェッカーユーザーローカル九段理江東京都同情塔4Dオブジェクト生成モデルAlign Your GaussiansAYGMAV3Dファーウェイ4D Gaussian Splatting4D-GSGlazeWebGlazeNightShadeSpawningHave I Been Trained?FortniteUnreal Editor For FortniteVolumetricsAIワールドジェネレーターRosebud AI GamemakerLayerCharisma.aiMeta QuestIP強いAI弱いAILumiereUNetImageFXMusicFXTextFXKeyframerGemini 1.5AI StudioVertex AIChat with RTXSlackSlack AIPokémon Battle Scopekanaeru占い行動ロジック生成AIConvaiNTTドコモEmemeGenie汎用AIエージェントAIファッションウィークGrok-1Mixture-of-ExpertsMoEClaude 3Claude 3 HaikuClaude 3 SonnetClaude 3 Opus森永乳業C2PAゲーミフィケーションTomo KiharaPlayfool遊びtsukurun地方創生吉田直樹素材OpenAI JapanVoice EngineCommand R+Oracle Cloud InfrastructureGoogle WorkspaceUdio立命館大学京都精華大学TacticAINPMPFOOHProject AstraGoogle I/O 2024感情認識音声加工マルタ大学田中達大Move AIICRA2024大規模基盤モデルTorobo東京ロボティクスインピーダンス制御深層予測学習日立製作所尾形哲也AIREC汎用ロボットオムロンサイニックエックスViLaInPDDLニューサウスウェールズ大学Claude Sammutオックスフォード大学Lars Kunze杉浦孔明田向権VASA-1VoxCeleb2AniTalker上海大学LumaDream MachineNTTAI野々村真GPT-4-turbo佐藤恵助大道麻由物語構造分析慶応義塾大学渡邉謙吾ここ掘れ!プッカ大柳裕⼠加納基晴研究開発事例赤羽進亮UDI(Universal Duel Interface)第一工科大学小林篤史荻野宏実ビヘイビアブランチWPPGeneral Computer Control(GCC)CradleSpiral.AIItakoLLM-7b静岡大学明治大学北原鉄朗中村栄太日本大学ヤマハ前澤陽増田聡採用科学史AIサイエンティストTerraAI Overview電通AICO2BitSummit DriftOmega CrafterSPACE INVADIANS西島大介吉田伸一郎SIGGRAPH2024Motion-I2VToonify3D生成対向ネットワーク拡散モデルDiffusionうめ小沢高広ドリコムai andSaaSインサイトカスタマーサポートComfyUI-AdvancedLivePortraitGUIVideo to VideoiPhone 16OpenAI o1AIスマートリンクシャープウェアラブルCE-LLMCommunication Edge-LLMAIペットYahoo!ニュースAI Comic FactoryAI comic GeneratorComicsMaker.aiLlamaGen.aiGAZAIFlame Planner動画ゲーム生成モデルVirtuals ProtocolMarioVGG松原卓二Art Transfer 2Art Selfie 2Musical CanvasThe Forever LabyrinthRefik AnadolAlexander RebenRhizomatiksMolmoPixMoQwen2 72BDepth ProVARIETASAI面接官キリンホールディングス空間コンピューティングDream ScreenFirefly Video ModelStable Video 4DAI受託開発事例田中志弥Playable!3DAdobe MAX 2024IllustratorMeta Quest 3XR-ObjectsOrion防犯O2Scam DetectionLive Threat Detection乗換NAVITIMEKaedim3DFY.aiLuma AIAvaturnBestatOasisDecartDejaboom!UnboundedEtchedパブリシティ権日本俳優連合日本芸能マネージメント事業者協会日本声優事業社協議会IAPPTripo 2.0Meta 3D Genスマートシティ都市計画松本雄太Genie 2World LabsCybeverThird Dimension AI東北大学Gemini 2.0フロンティアワークスSimplifiedAI Voice over GeneratorAI Audio EnhancerエーアイAITalkコエステーションPlayStationVRMLTechno Magicゴーストバスターズスパイダーマンポリフォニー・デジタル荒牧伸志AlteraRobert YangProject AVAStreamlabsIntelligent Streaming AssistantProject DIGITSスーパーコンピューターエージェンテックAI Shortsテルアビブ大学DiffUHaulTrailBlazerヴィクトリア大学ウェリントンzeroscopeQNeRFカーネギーメロン大学RALFグラフィックメイクCanvasProjectsDeepSeek-R1LoopyリップシンクCyberHostOmniHuman-1CSAMImagen 3Google LabsMicrosoft Museゲーム生成モデルWHAMデモンストレーターChatGPT Edu滋賀大学キリンビール桜AIカメラSolist-AIロームFactorioカリフォルニア大学GamingAgentClaude 3.7 SonnetFactorio Learning EnvironmentFLEDeepseek-v3Gemini-2-FlashLlama-3.3-70BGPT-4o-MiniZOZO NEXTZOZOFashion Intelligence SystemPartial Visual-Semantic EmbeddingWEARGPT-4Vソイル大学AIパズルジェネレーターDolphinGemmaWild Dolphin ProjectSoundStreamトークナイザー音声処理技術GPT-4.1GPT-4.1 miniGPT-4.1 nanoLINE AILINE AIトークサジェストGTC2025Fuxi LabNaraka:Bladepoint MobileバトルロイヤルビヘイビアツリーSoftServeALNAIRAMRIBLADEGAGAQUEENRunway Gen-4SkyReelsStable Virtual CameraIntangibleブライアン・イーノEnoBrain OneAlphaEvolveContinuous Thought Machine(CTM)ArmStable Audio Open SmallWord2WorldSTORY2GAMEウィットウォーターランド大学森川の頭の中花森リドGoogle I/O 2025Lyra 2MusicFX DJAnimon.aiツインズひなひまMayaDeep Q-LearningAlphaGOスペースインベーダープリンス・オブ・ペルシャドラゴンクエストIV堀井雄二山名学タイトーカプコンUbi AnvilエンジンV1 Video ModelArtificial AnalysisVideo ArenaVideo Model LeaderboardClaude 3.5Mistral樋口恭介Claude 4小川 昴ホラーゲームStable Diffusion 1.5階層型物語構造夏目漱石漱石書簡京都情報大学院大学上野未貴ブラウザCometKiroAww Inc.Visual BankTHE PENFUJIYAMA AI SOUND富士通西浦めめヘッドウォータース下斗米貴之ディプロマシーCluade Opus 4ChatGPT o3カリフォルニア大学サンディエゴ校Everyテトリス逆転裁判ロゼッタ広報MavericksNoLang 4.0gpt-oss金井大組織作りCygnusTaurus笠原達也バグチケット都築圭太仁木一順ライフレビューSIGGRAPH 2025Text-to-MotionMiegakureSide InternationalRazer Cortex: Playtest Program - Powered by SideStable Audio 2.5Veo 3 FastDynamics LabMagica 2Mirage 2ペンシルバニア大学コーネル大学HOLODECK 2.0市場調査GoogleクラウドゲームエイトQ-STAR小栗伸重藤井啓祐水野弘之AnimeGamer香港城市大学ニューヨーク大学God's Innovation ProjectGIPマインドスポーツチェスGrok 4華南理工大学池上⾼志ミュージックビデオTOWA TEI椎名林檎中村剛森山尋西健一スキップE-ONEPICTOY任天堂ギフトピアちびロボ!いきものづくりクリエイトーイ大盛り! いきものづくりクリエイトーイドラゴンリーグドラゴンポーカー城とドラゴンkoROBOコンパニオンAIcharacter.aiNomi.aiMETA LOOP DESIGN LTD.MEOHiClubSynClubStarleyCotomoLivetoonkaiwaコンパニオンロボットヒューマノイドRealbotix顔認識Cluade1XNEOジュネーブ大学NadineMIXIPanasonicNICOBOGemini Robotics 1.5XR BlocksLLMERペンシルバニア州立大学SIMA 2日本IBMシリアスゲームセガXDAI俳優世永玲生Adobe MAX 2025Gemini 3GenTabsDiscoイレブンラボジャパン日本郵便年賀状#Geminiで年賀状Nano Banana ProENCODE Jewelry Planner (AI)EncodeRingJewelry DesignerStory Jewelry DesignerAI JEWELRY MODEL中国・西安交通大学LacAIDes工芸宝飾品ソウル文化高等学校MineDojoText-to-VideoOmnimatteZeroSnapX-UniMotionDreamO人工知能のための哲学塾犬飼博士瀬尾浩二郎SteamLarian StudiosDivinityClair Obscur: Expedition 33Indie Game AwardPlaytikaKraftonTranslateGemmaChatGPT ヘルスケアマインスイーパーバイブコーディングGPT-5.1-Codex-MaxClaude Opus 4.5Gemini 3 ProGame ArenaポーカーGemini 3 Pro PreviewGPT-5.2polarixSo Long SuckerTextQuestsProject GenieClaude Opus 4.6快手(Kuaishou)Kling AI
【ICRA2024】大規模基盤モデルとロボットの連携による新たな可能性
2024.5.28先端技術

ロボティクスの国際会議「ICRA2024」、横浜で開催

2024年 5月13日~17日の5日間にわたって、米国電気電子学会(IEEE)が主催する「International Conference on Robotics and Automation(ロボット工学とオートメーションに関する国際会議、略称:ICRA )」がパシフィコ横浜で開催されました。日本でICRAが開催されたのは3回目、2009年の神戸での開催以来、15年ぶりです。
ICRA(読み方はアイクラ。イクラ派もいます)は、ロボット分野では影響力の大きいいわゆるトップカンファレンスの一つとして知られており、最先端のさまざまな研究が発表されます。今回の論文採択率は45%だったそうです。
現地参加費はIEEEのメンバーは 215,000円、メンバー以外は263,800円。1日参加費は80,000円。加えて、ワークショップ参加費は別途必要となります。円安とはいえ、かなりの金額です。最初見たとき、何かの間違いかと思って桁数を数えてしまいました。その結果でしょうか、日本での開催にもかかわらず、特にカンファレンス会場では海外勢の姿ばかりが目立ちました。

展示会場は大盛況
一方、展示会場では100を超える世界各国のロボット関連企業スポンサーのブースが立ち並び、下手な展示会よりも活況でした。特に目立ったのは中国勢を中心としたヒューマノイド(人型ロボット)の出展です。すごい盛り上がりで通路がまったく通れなくなっていたブースもありました。
通常の展示会ならば運営や向かいのブースから怒られるところですが、学会は基本的に運営ルールが全体的にゆるいのが一般的です。多くのロボットが入れ替わり立ち替わり通路をウロウロしており、非常に楽しい空間になっていました。
展示会場ではスポンサー展示だけではなく、「ICRA-EXPO」と呼ばれる日替わりの実物デモゾーン、ポスター発表、そして11を超えるロボット競技会も行われていました。ロボットは「動いてなんぼ」なので、これは当然と言えます。
また会場が横浜ということで、3月末に横浜でのイベントを終了したばかりの「動くガンダム」の頭部とハンドも展示されており、その前では海外からの参加者たちも思い思いに写真を撮っていました。

ロボットをより柔軟かつロバストに
さて、本題に入ります。いま、少なからぬ人たちがロボットに汎用性、すなわちこれまでにない理解力や環境適応力を持たせるために「大規模基盤モデル」が使えるのではないか、と考えています。単に「ChatGPTをコミュニケーションロボットに使って、色んなやりとりをさせよう」といった話だけではありません。大規模基盤モデルは大量のデータを、Transformerアーキテクチャーの大規模なニューラルネットワークに学習させることで、専門家たちも驚くほどの大きな成果を上げました。「言語の確率モデル」という範囲にとどまらず、言語を通してまるで世界の常識のようなものまで表現されているようです。
ロボットの世界とAIの世界との間には距離があると思っている読者もいらっしゃるかもしれませんが、たとえば、今は「ChatGPT」で世界的に知られるOpenAI社が、2018年ごろは強化学習を使ってロボットハンドでさまざまなものを扱うことができるようにする研究を行なっていました。ですが途中で行き詰まったのか、いったん大規模言語モデルの開発に舵を切って今に至っているという経緯があります。彼らが最近になって再びロボットに手を出しはじめているのは原点回帰と言えます。いったんロボットの難しさを知った上で戻ってきているわけで、成り行きが大いに注目されます。
では、どんなことが期待されているのでしょうか。手法は多少異なっていても目指すところはほぼ同じで、ロボットが自然言語による曖昧な指示の意図を理解し、プログラミングレスで未知環境でも自在に行動でき、未知の物体も適切に扱えるようにしようというものです。さらに、世界の物理的な振る舞いを反映する世界モデルと、さまざまなロボットにも転移学習させることが可能な大規模な行動データセットを整理して提供しよう、あれこれ頑張ればロボットがもっと賢くなるはずだという考え方です。
ロボットの動作の生成にも大規模基盤モデルが期待されています。いまや生成AIは動画も作れるようになりました。つまり、このエージェントは、こういう環境ではこう動くだろうということが、ある程度の範囲ならば辻褄を合わせたかたちで予測されて生成できるようになったことを意味しています。それと同じようなことが、さらにマルチモーダルかつ多様なデータを食わせれば、ロボットの動作生成においても可能なのではないか。そう考えられているわけです。つまりロボット動作基盤モデルの可能性です。
学習に必要なデータについては、実機からの収集に留まらず、人間による遠隔操作などで、ある程度集めた実データをもとに、シミュレーターを使って水増しして作ればいいという考え方もあります。動作データセットを作るためのロボットシステムなども考案されています。
LLMとの連携に向いたロボット

会場に出展されていたロボットにも機械学習の応用研究に適用できることをアピールしているものが多数ありました。たとえば早稲田大学発のスタートアップ・東京ロボティクスのToroboは「LLMとの連携に向いている」とCEOの坂本義弘氏は語りました。Toroboの特徴は全軸にトルクセンサがあり、インピーダンス制御によって柔らかく動かせる体を持っている点です。表面は硬いのですが、一般的なロボットが行なっている位置制御と違って対象にぶつかっても柔らかく制御できるのです。片腕を持って動かすと全身がふわっと動きますし、首をぐるぐると動かすこともできます。
ロボットがもっと役に立つ作業を行うためには必ず何かと接触しなければなりませんが、この接触が難しいのです。生成AIでロボットの動作が作れるようになったとしても、実環境と世界モデルのあいだには必ずギャップがあり、間違った場所にロボットがリーチすると、ロボットが壊れてしまう可能性もあります。そのときに体を柔らかく制御できるインピーダンス制御であれば環境になじむことができるので、ロボットは壊れません。だから今後のAIとの連携に向いている、というわけです。
なおToroboは人よりも少し大きなサイズですが、現在、もっと軽く高速化したモデルを開発中とのことです。なお同社は物流アプリケーションも展開しているので、そのデータも反映させていきたいと考えているということでした。これまで同社は国内のムーンショットプロジェクトなどにロボットを販売してきましたが、今後は海外のビッグテックにも売っていきたいと考えているそうです。
ICRA2024の会場では、他にもいかにもライバルっぽいロボットも出展されていました。今後の切磋琢磨が楽しみです。
AI研究者の見方とロボット研究者の見方
さて話を戻しますが、ここで一気にロボットの性能に革命が起きる可能性もなくはありません。多くの人が、そう期待しています。ただ一方で、AIの研究者たちとは違って、ロボットの研究者たちは必ずしも楽観はしていない…、そんな空気も感じました。
先程の話の繰り返しですが、シミュレーターでうまくいったからといって物理世界でうまくいくとは限りません。CGでそれっぽい動きを作ることはできても、実世界とは必ずズレがあります。重力や慣性、接触による摩擦やノイズのある環境では、シミュレーターのとおりには動きません。
ロボット研究者たちはこれまでも、こういった物理的な問題にずっと苦しんできました。そのため、単にあれこれ思い描くだけではなく、物理的な動作を伴うロボットの制御に関しては「そんなに簡単ではないだろう」と思っているようです。ですがそれでも、今度こそは革命的なことが起こるのではないかと多くの人が期待している。そんな状況です。
ロボットに汎用性が必要とされている理由
汎用性がなぜそこまで必要なのでしょうか。単純に言えば、世界が複雑だからです。ロボット適用を目指す領域はさまざまです。ロボットにはアカデミアの他、産業用ロボットの世界とサービスロボットの世界があって、それぞれ評価基準が大きく異なりますが、いずれの領域においても、ロボットが柔軟かつロバストな存在になることが求められています。
産業用の世界では基本的には決まりきった動きをするわけですが、いまだにロボットが苦手な作業対象があります。また、最近は「変種変量」生産に対応する必要があり、そのためにいちいち再プログラミングするのは現実的に困難であるため、自動化しきれない部分が残っています。
人に対してサービスを提供することもあるサービスロボットの世界での適応能力の必要性は言うまでもありません。ロボットのセンサーの機能や移動経路計画のスキルはだいぶ向上してきましたが、工場や倉庫と違って、きれいに整理整頓されていない場所でロボットを動かして作業させることは今もとても困難です。また、接する人もさまざまです。
「掃除だけ」とか、「物をAからBへ運ぶだけ」といった作業にとどまらず、サービス領域でロボットがさらに活躍できるようにするためには、ある程度の汎用性が必要です。
モデルは不完全だと考える深層予測学習のパワー
しばらく前から深層予測学習を提案しているのが日立製作所と早稲田大学理工学術院の尾形哲也教授らです。ロボットは学習内容から未来の状況を予測しながら行動することで、未知の環境に適応します。ICRA 2024ではドアを開けて通ったり、洗濯物を取り込むといったデモを披露していました。
デモだけ見れば「なんだそんなことか」と思うでしょう。何が難しいのでしょうか。ドアにはいろんな種類があり、開け方が違います。洗濯物は毎回かたちが異なり、常にふらふらと変形しています。つまり「どこをどう見るべきか、どこをつまんでどんな力をかければいいか」は、毎回異なるのです。それを自律でやらせようという試みです。
深層予測学習では、事前にすべての状態に対応する予測モデルを作ることは不可能だと考えて、最初から「モデルは不完全だ」と考えます。そして現在の状況とモデル予測誤差を最小化しようとするアルゴリズムを採用しました。学習には、ロボットの片目からの入力画像と、間接角、手先の触覚のデータが全て使われています。いわゆるマルチモーダル学習です。
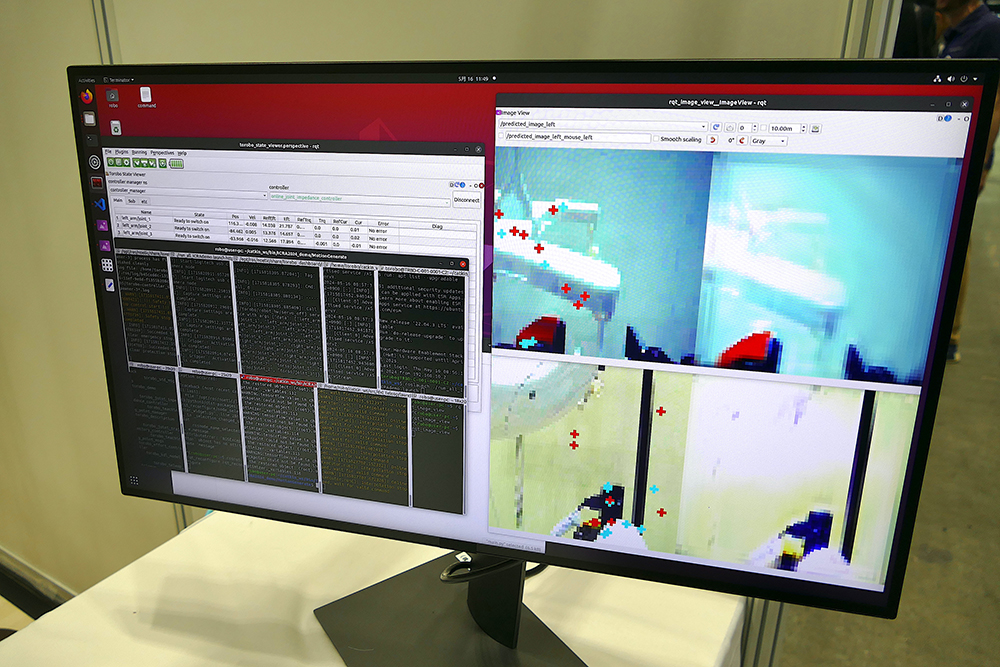
ネットワークはロボットがどこを見ているかを示す注意機構を予測学習の枠組みで学習させることができます。どういうことかというと、全体としてはロボットのセンサー値が予測結果として出力されるのですが、「タスク成功のためにはどこを見るべきか」という情報は、学習の過程で自動的に学習されるのです。
ロボットは誤差を最小化するために動作を調整し続け、不定形な物体に対しても重要な部分だけ見ることになります。教示データはデモンストレーションデータだけです。まさにEnd-to-Endで、いちいちつかむべき場所などを教える必要はありません。この考え方により、照明条件などが変動するなかでもロバストにタスクを成功させられるようになったそうです。もっとも、会場のデモでもうまくいったり行かなかったりでしたが、今後に期待したいところです。
向かいのブースではJSTムーンショット目標3で進められているAIRECという汎用ロボットを目指す研究のデモとして、台拭きや卵料理も行われていました。
将来は人と一緒に料理するロボットも?
オムロンが2018年に設立した研究子会社・オムロンサイニックエックスからは、今回のICRA2024に6件の論文が採択されたというリリースが出ていました。「人と機械の融和」を目指す彼らが掲げている技術テーマの一つが、AIとロボティクスの活用です。
具体例の一つとしては、調理の手順やコツを人間から学べるロボットの開発等を進めています。たとえばレシピサイトを見ると、色々な食材の写真や調理手順が掲載されていますが、そのような調理レシピを画像から自動生成し、ロボットが実行可能なかたちに変換する仕組み(タスクプランニング)などを研究開発しています。将来は人と一緒にロボットが調理をしてくれる世界を目指すものです。より一般的には「現状を認識しながら人の指示に従えるロボット」ということになります。
今回発表された「ViLaIn(Vision-Language Interpreter for Robot Task Planning)」というフレームワークは、大規模言語モデルと従来の記号的プランナーをつなぐためのものです。大規模言語モデルは言語による指示をロボットのプランに変換することが可能です。ただし、ロボットが実行可能な出力を出してくれるとは限りません。そこで、論理的に正しいプランを得るために古典的プランニングと大規模言語モデル、それぞれの長所を組み合わせようという考え方です。
大規模言語モデルと視覚言語モデルを使って、言語指示とシーン観察から従来型のプランナー向けの問題の記述を生成します。問題は「PDDL(Planning Domain Definition Launguage)」という形式で記述されます。次に生成された記述に基づいて有効なプランを見つけるために記号プランナーを走らせます。評価指標を考案し、実験を行った結果、99%以上の精度で正しい問題を生成し、58%以上の精度で有効な計画を生成できたとのことです。
他にも、柔らかい体を持つロボットを深層強化学習で制御する研究などを行なっています。ロボット業界では古典的なペグインホールという「穴にものを入れる」タスクがあるのですが、それをフニャフニャの手首のロボットと、ロボット自身のセンサーのみを使って記憶ベースのエージェントを学習させたところ、うまくできるようになったとのことです。
こういった研究が実用へと繋がるかは分かりませんが、今回、ICRAに6本の論文が通過していることからも、オムロンサイニックエックスが今の世界的研究トレンドにのっとった研究を行っていることは確かなようです。
汎用サービスロボットへの長い道のり

筆者が参加したフォーラムのテーマは「Foundation Models and Architectures for Service Robots in the Future Home(未来の家のサービスロボットのための基盤モデルとアーキテクチャ)」でした。GPSR(General Purpose Service Robot)と言われる汎用サービスロボットや家庭用サービスロボットを開発するための試みと、汎用ロボットを目指す競技会の一つ「ロボカップ@ホーム」への最近の技術的影響が議論されました。
コンピュータビジョンの進歩やディープラーニングによって、ロボットによる物体検出や人物追跡、話者認識などは大幅に楽になっています。ですが機械学習は必ずしも万能ではありません。基本的に大きなデータセットが必要だからです。そのデータ量を減らす手法が必要とされています。オーストラリア・ニューサウスウェールズ大学教授の Claude Sammut氏は、そのための方法として、強化学習を行う前に、その制約条件を得るための定性的なモデルの獲得が必要だと述べました。
オックスフォード大学教授のLars Kunze氏は「ロボットを説明可能、安全、信頼できるものにする」と題して講演しました。ロボットが実際のオフィスや家庭に入るためには、ロボット自体が何を知っているのかを外に説明する必要があります。フランス・ブレスト国立工科大学教授のCédric Buche氏は最初にデータプライバシーの問題について強調しました。
パネルディスカッションではサービスロボットが家庭に普及しない理由、そもそもどんなサービスが期待されているのか、規制の課題など、色々なテーマに関する議論が行われました。会場からは例えば「家庭用にロボットを開発することを想定した場合、特定のタスクをいくつか選んでフォーカスしたほうがいいのか、あるいはもっと漠然とした用途に対応したり会話の相手をしてあげるロボットを開発したほうがいいのか、どちらのほうがメリットがあると思うか?」といった質問が寄せられました。これは技術の話だけではありませんので、なかなか正解は出ない問題ですが、「人間と直接比較されるようなタスクをロボットにやらせることは得策ではないだろう」という話が出ていました。
基盤モデルの活用についても議題に上がりました。パネリストの一人だった慶應義塾大学教授の杉浦孔明氏は「対話における自然言語処理や状況認識など多くの課題が今はLLMひとつでカバーできるようになり、サービスロボットの開発は以前より明らかに簡単になった」とコメントしました。
実際に会場でも行われていたのですが、確かに、最初の指示を理解するタスク、いわゆる自然言語処理タスクや、状況そのものの理解に関しては、以前よりも大幅に楽になったようです。でもロボット競技大会では、今でも出場者たちはさまざまなオブジェクトの大きさを巻尺で測ったりしています。以前より楽にはなったとは言っても、いわゆるゼロショットで何でもできる汎用ロボットへの道は、まだ遠いのです。「常識」を提供する世界モデルや、さまざまなロボットに適用可能な汎用的なスキルセットのようなものが必要です。
また先程のオムロンサイニックエックスのところでも出た話ですが、従来の形式的手法と大規模言語モデルの間の対応関係を見つけて利用することが重要だ、という話も出ました。このあたりが妥当な意見なのでしょう。
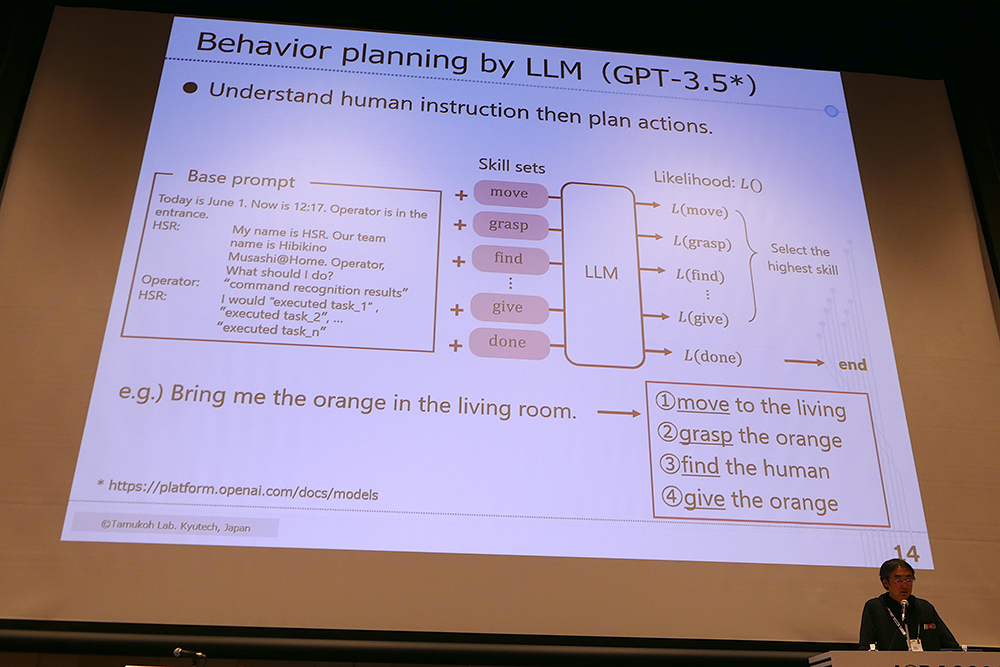
脳型情報処理の研究者であり、Hibikino-Musashiというチームで「ロボカップ@ホーム」の常連である九州工業大学教授の田向権氏は、環境における記憶のモデリングを使った処理や、小さなニューラルネットワークモデルで時系列データを扱って、ロボカップの課題を解く研究について紹介しました。ロボカップの課題とは、たとえば朝食の配膳準備をしたり、未知のレストランでサーブをするといったものです。行動プランナーには大規模言語モデルを使っているのですが、今でもこれらはとても難しい課題だと田向氏は語りました。今はまだ「大規模基盤モデルを使えば全部終了」というわけにはいきそうにありません。ですが挑戦は続きます。
急接近するロボットとAIの未来は
歴史を振り返ると、もともとロボットと人工知能は、互いに両輪のように発展してきた分野です。しかし両者のあいだはいつしか大きな距離ができていたことも、また事実です。ですがここに来て両者が急激に接近しようとしてる気配があります。
モデル学習のために実世界のマルチモーダル・データを収集するためにはロボットが必要ですし、実世界に物理的に直接影響を与えようと思ったらロボットを使うのがもっとも単純です。ロボットのほうも、今まではずっと人間により制御されてきましたが、今後は本当に自らのセンシングによる知覚、完全自律での判断と知覚情報の変換、そしてアクションを行えるようになるのかもしれません。
大規模言語モデルが急にブレイクして一般の人でもわかるくらい進展したように、ロボットが自在に動かせるようになったら、大きな変化が社会にもたらされる可能性があります。どれだけうまくいくのか現状では不透明ですが期待したいと思っています。
Writer:森山和道



 RANKING
RANKING



