

モリカトロン株式会社運営「エンターテインメント×AI」の最新情報をお届けするサイトです。
- TAG LIST
- CGCGへの扉生成AI吉本幸記安藤幸央月刊エンタメAIニュース河合律子LLMOpenAI大規模言語モデル機械学習ディープラーニンググーグルGoogle音楽NVIDIAChatGPTモリカトロン森川幸人GAN三宅陽一郎DeepMind強化学習Stable Diffusion人工知能学会シナリオニューラルネットワークQAマイクロソフト倫理自然言語処理SIGGRAPHAIと倫理GPT-3映画スクウェア・エニックス大内孝子アートFacebook音楽生成AIルールベース著作権3DCG動画生成AIキャラクターAINPCデバッグ敵対的生成ネットワークアニメーションロボットゲームプレイAIMinecraftモリカトロンAIラボインタビュープロシージャルディープフェイクNFT画像生成VFXファッションStyleGANDALL-E2マルチモーダルRed RamGeminiAdobe遺伝的アルゴリズムメタAI教育自動生成テストプレイMidjourneyVR小説ボードゲームマンガMetaStability AI画像生成AIGPT-4oインタビューゲームAI不完全情報ゲーム深層学習CEDEC2019toioMicrosoftマインクラフトCLIPテキスト画像生成Playable!NeRFSoraビヘイビア・ツリー広告DALL-ECEDEC2021バーチャルヒューマンデジタルツインメタバースELSI高橋力斗作曲アストロノーカロボティクスナビゲーションAI畳み込みニューラルネットワークARアップルSIGGRAPH ASIAスポーツ手塚治虫汎用人工知能3DCEDEC2020AIアートはこだて未来大学エージェントGDC 2021アドベンチャーゲームメタ市場分析デジタルヒューマン東京大学JSAI2022プロンプトGPT-4CMGDC 2019マルチエージェントHTNソニー栗原聡CNNマーケティング懐ゲーから辿るゲームAI技術史鴫原盛之NVIDIA OmniverseCEDEC2022ジェネレーティブAIDALL-E 3言霊の迷宮ブロックチェーン人狼知能音声認識Ubisoft階層型タスクネットワークYouTubeJSAI2020Microsoft Azure模倣学習Unityインディーゲーム音声合成BERTチャットボットOmniverseRobloxがんばれ森川君2号NetflixGPT-3.5AIQVE ONE世界モデルGTC2023JSAI2023電気通信大学AppleJSAI2024イベントレポート対話型エージェントシーマン水野勇太ガイスター斎藤由多加SF研究シムシティシムピープルTEZUKA2020スパーシャルAIElectronic ArtsメタデータTensorFlowキャリアAmazonDQNSIEアバターGenvid TechnologiesStyleGAN2JSAI2021ZorkMCS-AI動的連携モデルモーションキャプチャーAGI高橋ミレイCygamesサイバーエージェント合成音声モリカトロン開発者インタビュー宮本茂則AWS徳井直生GTC2022Unreal Engineテキスト生成デザイントレーディングカードメディアアートtext-to-imageAdobe MAXOpen AIベリサーブ音声生成AI松木晋祐BardControlNetブラック・ジャック村井源稲葉通将ユニバーサルミュージックマーダーミステリーCEDEC2023LoRAXRVeoRunwayGPT-5Amadeus CodeeSportsお知らせワークショップクラウドAlphaZeroAIりんなカメラ環世界中島秀之宮路洋一理化学研究所テンセント人事DARPAドローン人工生命ASBSぱいどんAI美空ひばり手塚眞GDC Summer岡島学eスポーツスタンフォード大学テニスBLUE PROTOCOLaibo銭起揚自動運転車TransformerGPT-2シミュレーション哲学現代アートバンダイナムコ研究所ELYZAELIZANVIDIA RivaEpic GamesrinnaSNS松尾豊データマイニングゲームエンジンImagenバイアスサム・アルトマンNEDO森山和道自動翻訳アーケードゲームセガ類家利直大澤博隆SFプロトタイピングコナミデジタルエンタテインメントtext-to-3DDreamFusionAIロボ「迷キュー」に挑戦Preferred NetworksPaLMGitHub CopilotGen-1大阪大学建築イーロン・マスクStable Diffusion XLAudio2FaceGoogle I/OFireflyTikTok立教大学KLabLLaMAハリウッドテキスト画像生成AI法律論文Niantic新清士Apple Vision ProByteDanceCEDEC2024Runway Gen-3 AlphaスーパーマリオブラザーズWhiskSIGGRAPH Asia 2024DeepSeekGDCモリカトロンAIコネクトClaudeAnthropicGDC 2025モリカコミックVeo 3JSAI2025OpenAI o3CEDEC2025Sora 2OpenAI Fiveピクサービッグデータナラティブエージェントシミュレーション眞鍋和子齊藤陽介成沢理恵Magic Leap Oneサルでもわかる人工知能リップシンキングUbisoft La Forge知識表現IGDAどうぶつしょうぎジェイ・コウガミ音楽ストリーミングマシンラーニング5G対話エンジンシーマン人工知能研究所ゴブレット・ゴブラーズ完全情報ゲームウェイポイントパス検索藤澤仁画像認識DeNA長谷洋平ぎゅわんぶらあ自己中心派ウロチョロスNBAフェイクニュースウィル・ライトレベルデザインGPUALifeオルタナティヴ・マシンサウンドスケープTRPGAI Dungeonゼビウス不気味の谷写真松井俊浩パックマン通しプレイ本間翔太馬淵浩希中嶋謙互FPSレコメンドシステム軍事PyTorchモンテカルロ木探索バンダイナムコスタジオ田中章愛サッカーバスケットボールVAERNNウォッチドッグス レギオンHALOMITMuZeroRival Peakリトル・コンピュータ・ピープルコンピューティショナル・フォトグラフィー絵画坂本洋典釜屋憲彦生物学StyleCLIPmasumi toyotaTextWorldBingMagentaGTC2021CycleGANNetHackAIボイスアクター南カリフォルニア大学NVIDIA CanvasNetEaseナビゲーションメッシュ深層強化学習ELYZA DIGESTLEFT 4 DEADプラチナエッグイーサリアムボエダ・ゴティエOmniverse ReplicatorNVIDIA DRIVE SimNVIDIA Isaac SimDisneyAI会話ジェネレーターグランツーリスモ・ソフィーVTuberフォートナイトQosmoポケモンCodexSoul Machinesバーチャルキャラクター対談GTC 2022SiemensクラウドコンピューティングOpenSeaGDC 2022Earth-2エコロジーELYZA Pencil医療キャラクターモーションRPGSIGGRAPH 2022LaMDAマジック:ザ・ギャザリング介護Romi松原仁武田英明フルコトデータ分析MILEWCCFWORLD CLUB Champion Football柏田知大田邊雅彦トレカMax Cooper京都芸術大学ラベル付け秋期GTC2022野々下裕子pixivセキュリティ3DスキャンMicrosoft Designerイラスト柿沼太一ScenarioAIピカソAI素材.comAndreessen HorowitzQA Tech Night下田純也桑野範久対話型AIモデルnoteDreamerV3Blenderゲーム背景Point-EアパレルBIMGPTPhotoshopChatGPT4コミコパTencentTEZUKA2023大阪公立大学オムロン サイニックエックスFastGAN橋本敦史宮本道人LLaMA 2Hugging FacexAIストライキVoyagerIBMソフトバンクSIGGRAPH2023音源分離Web3BitSummitファインチューニンググランツーリスモ量子コンピュータ北野宏明立福寛FSM-DNNMindAgent効果音NVIDIA ACE慶應義塾大学ヒストリアAI Frog InteractiveComfyUISuno AIKaKa CreationVOICEVOXGPTs3D Gaussian SplattingGDC 2024調査ポケットモンスターインフルエンサーSIMAGemma 2Inworld AIIEEE早稲田大学Apple IntelligenceWWDCWWDC 2024Perplexityくまうた濱田直希ソニー・インタラクティブエンタテインメント遊戯王佐竹空良九州大学伊藤黎Sakana AILINEヤフーDOOMGameNGen社員インタビューMovie GenSynthIDPlayable!MobileSneaksPeridot声優早瀬悠真Veo 2機械翻訳SONYProject SidRazerCube 3DベンチマークHao AI Labジョージア工科大学MeshyFlowGemini 2.5-proGemini 2.5 Flash ImageKeep4oGenie 3Nano BananaEXPO2025大阪・関西万博アトラクチャー中村政義森旭彦Veo 3.1はらぺこミームSIGGRAPH Asia 2025ゲーム映像パラメータ設計バランス調整Dota 2ソーシャルゲーム淡路滋グリムノーツゴティエ・ボエダGautier BoedaJuliusTPRGバーチャル・ヒューマン・エージェントクーガー石井敦茂谷保伯マジック・リープノンファンジブルトークン里井大輝GEMS COMPANY初音ミク転移学習デバッギング北尾まどか将棋ナップサック問題SpotifyReplica Studioamuseクラウドゲーミング和田洋一StadiaSIGGRAPH 2019iPhoneAIGraph予期知能ドラゴンクエストPAIRアルスエレクトロニカ2019逆転オセロニア奥村エルネスト純齋藤精一高橋智隆ロボユニ泉幸典ロボコレ2019意思決定モデルLEFT ALIVE長谷川誠Baby Xロバート・ダウニー・Jr.The Age of A.I.レコメンデーションMOBA研修mynet.ai人工音声プレイ動画群知能Sporeデノイズ画像処理CPUGMAIウィザードリィ西川善司サムライスピリッツストリートファイター山野辺一記大里飛鳥13フェイズ構造Oculus Quest生体情報照明山崎陽斗立木創太GameGANソサエティ5.0SIGGRAPH 2020DIB-RApex LegendsNinjaTENTUPLAYMARVEL Future Fightタイムラプスバスキア階層型強化学習WANN竹内将セリア・ホデントUX認知科学ゲームデザインLUMINOUS ENGINELuminous Productionsパターン・ランゲージちょまどマルコフ決定過程協調フィルタリングAlphaDogfight TrialsStarCraft IIFuture of Life InstituteIntelLAIKARotomationドラゴンクエストライバルズ不確定ゲームEmbeddingGTC2020NVIDIA MAXINEビデオ会議階層的クラスタリングtoio SDK for UnityGDMCMITメディアラボMagendaDDSPKaggleAssassin’s Creed OriginsSea of ThievesmonoAI technologyOculusテストBaldur's Gate 3Candy Crush SagaSIGGRAPH ASIA 2020BigGANMaterialGANReBeLVolvoRival PrakユービーアイソフトメタルギアソリッドVFSM汎用言語モデルChitrakar巡回セールスマン問題ジョルダン曲線リアリティ番組ジョンソン裕子MILEsインタラクティブ・ストリーミングインタラクティブ・メディアLudoArtEmisGROVERFAIRチート検出オンラインカジノRealFlowDeep FluidsMeInGameブレイン・コンピュータ・インタフェースBCILearning from VideoユクスキュルカントエージェントアーキテクチャOCTOPATH TRAVELER西木康智OCTOPATH TRAVELER 大陸の覇者StyleRigいただきストリート大森田不可止ザナック仁井谷正充Azure Machine Learning脱出ゲームHybrid Reward ArchitectureSuper PhoenixProject MalmoProject PaidiaProject LookoutWatch Forジミ・ヘンドリックスカート・コバーンエイミー・ワインハウスダフト・パンクGlenn MarshallStory2HallucinationJukeboxSIFTDCGANDANNCEハーバード大学デューク大学ローグライクゲームNeurIPS 2021ヒップホップ詩サイレント映画環境音粒子群最適化法進化差分法下川大樹高津芳希大石真史BEiTDETRSentropyDiscordCALMプログラミングソースコード生成シチズンデベロッパーGitHubMCN-AI連携モデル並木幸介森寅嘉SIGGRAPH 2021半導体Topaz Video Enhance AIDLSSDynamixyzU-NetADVXLandDEATH STRANDINGEric JohnsonコジマプロダクションデシマエンジンMaxim PeterJoshua Romoffハイパースケープミライ小町テスラTesla BotTesla AI Dayバズグラフニュースタンテキ東芝倉田宜典韻律射影韻律転移コンピュータRPGアップルタウン物語KELDICメロディ言語AstroEgo4D日経イノベーション・ラボ敵対的強化学習GOSU Data LabGOSU Voice AssistantSenpAI.GGMobalyticsAWS Sagemaker形態素解析AWS Lambda誤字検出SentencePiece竹村也哉GOAPAdobe MAX 2021Omniverse AvatarNVIDIA MegatronNVIDIA MerlinNVIDIA Metropolisテキサス大学AI Messenger VoicebotOpenAI CodexHyperStyleRendering with StyleDisneyリサーチGauGANGauGAN2画像言語表現モデルSIGGRAPH ASIA 2021ディズニーリサーチMitsuba2ワイツマン科学研究所CG衣装VRファッションArtflowEponym音声クローニングGopher鑑定Oxia PalusArt RecognitionNHC 2021池田利夫新刊案内マーベル・シネマティック・ユニバースMCUアベンジャーズDigital DomainMasquerade2.0フェイシャルキャプチャー山田暉LSTMモリカトロンAIソリューションコード生成AIAlphaCodeCodeforces自己増強型AICOLMAPADOPGANverse3DグランツーリスモSPORTGTソフィーFIAグランツーリスモチャンピオンシップDGX A100Webcam VTuber星新一賞Live NationWeb3.0AIOpsスマートコントラクトメディア政治NightCafeLuis Ruiz東京工業大学博報堂ラップZ世代AIラッパーシステムプラスリンクス ~キミと繋がる想い~STCStyle Transfer ConversationRCPRinna Character PlatformAmeliaGateboxANIMAK逢妻ヒカリセコムバーチャル警備システム損保ジャパン上原利之アッパーグラウンド品質保証AutodeskBentley SystemsワールドシミュレーターH100COBOLDGX H100DGX SuperPODInstant NeRFartonomousbitGANsコミュニティ管理オンラインゲーム気候変動マックス・プランク気象研究所ビョルン・スティーブンス気象モデル気象シミュレーション環境問題SDGsメモリスタ音声変換Veap JapanEAP福井千春メンタルケアEdgar Handy東京理科大学産業技術総合研究所リザバーコンピューティングソニーマーケティングもじぱ暗号通貨FUZZLEAlterationオープンワールドAIFAP2EStyleGAN-NADAUnity for IndustryGLIDEAvatarCLIPSynthetic DataSonanticCohereUrzas.aiKikiZoetic AIペットDigital Dream LabsCozmoタカラトミーLOVOTMOFLINミクシィユニロボットユニボGato汎用強化学習AIロンドン芸術大学Google BrainSound ControlSYNTH SUPERKarl SimsArtnomeICONATE浜中雅俊福井健策WikipediaSphereXaver 1000養蜂Beewiseフィンテック投資MILIZE三菱UFJ信託銀行西成活裕群衆マネジメントライブビジネス新型コロナ周済涛清田陽司サイバネティックス人工知能史AI哲学マップ星新一StyleGAN-XLStyleGAN3GANimatorVoLux-GANProjected GANSelf-Distilled StyleGANニューラルレンダリングPLATOframe.ioFoodly中川友紀子アールティBlenderBot 3Meta AIマーク・ザッカーバーグWACULAIライティングAIのべりすとQuillBotCopysmithJasperヴィトゲンシュタイン論理哲学論考PromptBaseバンダイナムコネクサスユーザーレビューmimicBaiduERNIE-ViLG古文書凸版印刷AI-OCR画像判定実況パワフルサッカー桃太郎電鉄桃鉄パワサカ岩倉宏介PPOMachine Learning Project Canvas国立情報学研究所石川冬樹スパコンスーパーコンピュータ松岡 聡TSUBAME 1.0TSUBAME 2.0ABCI富岳Society 5.0夏の電脳甲子園座談会NVIDIA GET3DAI絵師UGCPGCNovelAINovelAI Diffusionモーションデータポーズ推定メッシュ生成メルセデス・ベンツMagic LeapEpyllionマシュー・ボールムーアの法則Adobe MAX 2022Adobe ResearchGalactica映像解析東芝デジタルソリューションズSATLYS 映像解析AIPFN 3D ScanPFN 4D ScanDreamUpDeviantArtWaifu Diffusion元素法典Novel AICALAアフォーダンスPaLM-SayCanCode as PoliciesCaPコリジョンチェック山口情報芸術センター[YCAM]YCAMアンラーニング・ランゲージカイル・マクドナルドローレン・リー・マッカーシー鎖国[Walled Garden]プロジェクトSIGGRAPH ASIA 2022VToonifyControlVAE変分オートエンコーダーフォトグラメトリ回帰型ニューラルネットワークDeepJoinAzure OpenAI ServiceDeepLDeepL Writeシンギュラリティレイ・カーツワイルヴァーナー・ヴィンジRunway ResearchMake-A-VideoPhenakiDreamixText-to-ImageモデルLatitudeneoAIDreamIconmignstudiffusenote AIアシスタントKetchupAI NewsArt SelfieArt TransferPet PortraitsBlob OperaクリムトクリティックネットワークアクターネットワークDMLabControl SuiteAtari 100kAtari 200MYann LeCun鈴木雅大コンセプトアートColie Wertzリドリー・スコット絵コンテストーリーボードPaLM APIMakerSuiteSkebDreambooth-Stable-DiffusionGoogle EarthGEPPETTO AIStable Diffusion web UIAI modelAI ModelsZMO.AIMOBBY’SモビーディックダイビングアウトドアAIスキャニング自動採寸3DLOOKSizerワコールスニーカーUNSTREETNewelseCheckGoods二次流通中古市場Dupe Killer偽ブランド配信ソニー・ピクチャーズ アニメーションFosters+PartnersZaha Hadid ArchitectsライブポートレイトWonder Studio土木インフラAmazon BedrockX.AIX Corp.TwitterXホールディングスMagiSDXLRTFKTNIKEClone X村上隆Digital MarkSnapchatクリエイターコミュニティバーチャルペットNVIDIA NeMo Serviceヴァネッサ・ローザVanessa A Rosa陶芸Play.ht音声AILiDARPolycamdeforumハーベストForGamesゲームマーケット岡野翔太郡山喜彦ジェフリー・ヒントンGoogle I/O 2023武蔵野美術大学BingAILightroomCanvaBOOTHpixivFANBOX虎の穴Fantiaとらのあな集英社少年ジャンプ+ComicCopilotゲームマスターInowrld AIMODGhostwriterSkyrimスカイリムRPGツクールMZChatGPT_APIMZダンジョンズ&ドラゴンズOracle RPG深津貴之xVASynthLaser-NVMERFAlibabaVQRFnvdiffrecNeRFMeshingLERFマスタリングリアム・ギャラガーグライムスBoomyジョン・レジェンドザ・ウィークエンドドレイクエッジワークス日本音楽作家団体協議会FCAVoiceboxさくらインターネットぷよぷよTCGQRコード囲碁デンソーデンソーウェーブ原昌宏日本機械学会ロボティクス・メカトロニクス講演会トヨタ自動車かんばん方式プロット生成4コママンガElevenLabsHeyGenAfter Effects絵本出版Ammaar ReshiStoriesStoryBirdVersedProlificDreamerUnity SentisUnity MuseCaleb Ward宮田龍清河幸子西中美和安野貴博斧田小夜CM3leonStable DoodleT2I-Adapter日本マネジメント総合研究所Lily Hughes-RobinsonColossal Cave AdventureAdventureGPTリリー・ヒューズ=ロビンソンBabyAGIGPT-3.5 Turboカーリングウィンブルドン戦術分析パフォーマンス測定IoTProFitXWatsonxAthleticaコーチング北見工業大学北見カーリングホール画像解析じりつくんNTT SportictAIカメラSTADIUM TUBEPixelllot S3AIスマートコーチDreamboothヤン・ルカンPerfusionニューラル物理学毛髪荒牧英治中ザワヒデキ大屋雄裕中川裕志Adreeseen HorowitzNVIDIA Avatar Cloud EngineReplica StudiosSmart NPCsRoblox StudioPromethean AIMusiioEndelSonarSonar+DDolby AtmosSonar Music Festivalライゾマティクス真鍋大度花井裕也Ritchie HawtinErica SynthUfuk Barış MutluJapanese InstructBLIP Alpha日本新聞協会AIいらすとやAI PicassoEmposyAIタレントAIタレントエージェンシーmodi.aiBitSummit Let’s Go!!デジタルレプリカGOT7synthesiaHumanRFActors-HQSAG-AFTRAWGAチャーリー・ブルッカー岡野原大輔自己教師あり学習In-Context Learning(ICL)qubitIBM Quantum System 2ダリオ・ヒルジェン・スン・フアンHuggingFaceStable Audio宗教仏教コカ・コーラ食品Coca‑Cola Y3000 Zero SugarCopilot Copyright Commitmentテラバース京都大学音声解析感情分析周 済涛ステートマシンディープニューラルネットワークハイブリッドアーキテクチャAdobe Max 2023Bing ChatBing Image CreatorAssistant with BardThe ArcadeSearch Generative ExperienceDynalangVLE-CEAI ActEUArs ElectronicaAI規制欧州委員会欧州議会欧州理事会MusicLMAudioLMMusicCapsAudioCraftMubertMubert RenderGen-2Runway AI Film FestivalPreVizCharacter-LLM復旦大学Chat-Haruhi-Suzumiya涼宮ハルヒEmu VideoペリドットDream TrackMusic AI ToolsLyriaYahoo!知恵袋インタラクティブプロンプトAI石渡正人手塚プロダクション林海象古川善規大規模再構成モデルLRMObjaverseMVImgNetOne-2-3-453Dガウシアンスプラッティングワンショット3D生成技術FGDCFuture Game Development Conference佐々木瞬Anique中村太一エグゼリオCopilotserial experiments lainAI lainPCGPCGRLDungeons&Dragonsビートルズザ・ビートルズ: Get BackDemucs音楽編集ソフトAdobe AuditioniZotopeRX10MoisesレベルファイブGenie AISIGGRAPH Asia 2023C·ASEFLAREダンスMagicAnimateAnimate Anyoneインテリジェントコンピュータ研究所アリババDreaMovingVISCUITScratchスクラッチビスケットプログラミング教育VALL-EDeepdub.aiAUDIOGENEvoke MusicAutoFoleyColourlab.AiディズニーLargo.aiCinelyticTaskadePika.artAI Filmmaking AssistantAI Screenwriter芥川賞文学恋愛タップルAbema TVNEC木村屋GPT Store生成AIチェッカーユーザーローカル九段理江東京都同情塔4Dオブジェクト生成モデルAlign Your GaussiansAYGMAV3Dファーウェイ4D Gaussian Splatting4D-GSGlazeWebGlazeNightShadeSpawningHave I Been Trained?FortniteUnreal Editor For FortniteVolumetricsAIワールドジェネレーターRosebud AI GamemakerLayerCharisma.aiMeta QuestIP強いAI弱いAILumiereUNetImageFXMusicFXTextFXKeyframerGemini 1.5AI StudioVertex AIChat with RTXSlackSlack AIPokémon Battle Scopekanaeru占い行動ロジック生成AIConvaiNTTドコモEmemeGenie汎用AIエージェントAIファッションウィークGrok-1Mixture-of-ExpertsMoEClaude 3Claude 3 HaikuClaude 3 SonnetClaude 3 Opus森永乳業C2PAゲーミフィケーションTomo KiharaPlayfool遊びtsukurun地方創生吉田直樹素材OpenAI JapanVoice EngineCommand R+Oracle Cloud InfrastructureGoogle WorkspaceUdio立命館大学京都精華大学TacticAINPMPFOOHProject AstraGoogle I/O 2024感情認識音声加工マルタ大学田中達大Move AIICRA2024大規模基盤モデルTorobo東京ロボティクスインピーダンス制御深層予測学習日立製作所尾形哲也AIREC汎用ロボットオムロンサイニックエックスViLaInPDDLニューサウスウェールズ大学Claude Sammutオックスフォード大学Lars Kunze杉浦孔明田向権VASA-1VoxCeleb2AniTalker上海大学LumaDream MachineNTTAI野々村真GPT-4-turbo佐藤恵助大道麻由物語構造分析慶応義塾大学渡邉謙吾ここ掘れ!プッカ大柳裕⼠加納基晴研究開発事例赤羽進亮UDI(Universal Duel Interface)第一工科大学小林篤史荻野宏実ビヘイビアブランチWPPGeneral Computer Control(GCC)CradleSpiral.AIItakoLLM-7b静岡大学明治大学北原鉄朗中村栄太日本大学ヤマハ前澤陽増田聡採用科学史AIサイエンティストTerraAI Overview電通AICO2BitSummit DriftOmega CrafterSPACE INVADIANS西島大介吉田伸一郎SIGGRAPH2024Motion-I2VToonify3D生成対向ネットワーク拡散モデルDiffusionうめ小沢高広ドリコムai andSaaSインサイトカスタマーサポートComfyUI-AdvancedLivePortraitGUIVideo to VideoiPhone 16OpenAI o1AIスマートリンクシャープウェアラブルCE-LLMCommunication Edge-LLMAIペットYahoo!ニュースAI Comic FactoryAI comic GeneratorComicsMaker.aiLlamaGen.aiGAZAIFlame Planner動画ゲーム生成モデルVirtuals ProtocolMarioVGG松原卓二Art Transfer 2Art Selfie 2Musical CanvasThe Forever LabyrinthRefik AnadolAlexander RebenRhizomatiksMolmoPixMoQwen2 72BDepth ProVARIETASAI面接官キリンホールディングス空間コンピューティングDream ScreenFirefly Video ModelStable Video 4DAI受託開発事例田中志弥Playable!3DAdobe MAX 2024IllustratorMeta Quest 3XR-ObjectsOrion防犯O2Scam DetectionLive Threat Detection乗換NAVITIMEKaedim3DFY.aiLuma AIAvaturnBestatOasisDecartDejaboom!UnboundedEtchedパブリシティ権日本俳優連合日本芸能マネージメント事業者協会日本声優事業社協議会IAPPTripo 2.0Meta 3D Genスマートシティ都市計画松本雄太Genie 2World LabsCybeverThird Dimension AI東北大学Gemini 2.0フロンティアワークスSimplifiedAI Voice over GeneratorAI Audio EnhancerエーアイAITalkコエステーションPlayStationVRMLTechno Magicゴーストバスターズスパイダーマンポリフォニー・デジタル荒牧伸志AlteraRobert YangProject AVAStreamlabsIntelligent Streaming AssistantProject DIGITSスーパーコンピューターエージェンテックAI Shortsテルアビブ大学DiffUHaulTrailBlazerヴィクトリア大学ウェリントンzeroscopeQNeRFカーネギーメロン大学RALFグラフィックメイクCanvasProjectsDeepSeek-R1LoopyリップシンクCyberHostOmniHuman-1CSAMImagen 3Google LabsMicrosoft Museゲーム生成モデルWHAMデモンストレーターChatGPT Edu滋賀大学キリンビール桜AIカメラSolist-AIロームFactorioカリフォルニア大学GamingAgentClaude 3.7 SonnetFactorio Learning EnvironmentFLEDeepseek-v3Gemini-2-FlashLlama-3.3-70BGPT-4o-MiniZOZO NEXTZOZOFashion Intelligence SystemPartial Visual-Semantic EmbeddingWEARGPT-4Vソイル大学AIパズルジェネレーターDolphinGemmaWild Dolphin ProjectSoundStreamトークナイザー音声処理技術GPT-4.1GPT-4.1 miniGPT-4.1 nanoLINE AILINE AIトークサジェストGTC2025Fuxi LabNaraka:Bladepoint MobileバトルロイヤルビヘイビアツリーSoftServeALNAIRAMRIBLADEGAGAQUEENRunway Gen-4SkyReelsStable Virtual CameraIntangibleブライアン・イーノEnoBrain OneAlphaEvolveContinuous Thought Machine(CTM)ArmStable Audio Open SmallWord2WorldSTORY2GAMEウィットウォーターランド大学森川の頭の中花森リドGoogle I/O 2025Lyra 2MusicFX DJAnimon.aiツインズひなひまMayaDeep Q-LearningAlphaGOスペースインベーダープリンス・オブ・ペルシャドラゴンクエストIV堀井雄二山名学タイトーカプコンUbi AnvilエンジンV1 Video ModelArtificial AnalysisVideo ArenaVideo Model LeaderboardClaude 3.5Mistral樋口恭介Claude 4小川 昴ホラーゲームStable Diffusion 1.5階層型物語構造夏目漱石漱石書簡京都情報大学院大学上野未貴ブラウザCometKiroAww Inc.Visual BankTHE PENFUJIYAMA AI SOUND富士通西浦めめヘッドウォータース下斗米貴之ディプロマシーCluade Opus 4ChatGPT o3カリフォルニア大学サンディエゴ校Everyテトリス逆転裁判ロゼッタ広報MavericksNoLang 4.0gpt-oss金井大組織作りCygnusTaurus笠原達也バグチケット都築圭太仁木一順ライフレビューSIGGRAPH 2025Text-to-MotionMiegakureSide InternationalRazer Cortex: Playtest Program - Powered by SideStable Audio 2.5Veo 3 FastDynamics LabMagica 2Mirage 2ペンシルバニア大学コーネル大学HOLODECK 2.0市場調査GoogleクラウドゲームエイトQ-STAR小栗伸重藤井啓祐水野弘之AnimeGamer香港城市大学ニューヨーク大学God's Innovation ProjectGIPマインドスポーツチェスGrok 4華南理工大学池上⾼志ミュージックビデオTOWA TEI椎名林檎中村剛森山尋西健一スキップE-ONEPICTOY任天堂ギフトピアちびロボ!いきものづくりクリエイトーイ大盛り! いきものづくりクリエイトーイドラゴンリーグドラゴンポーカー城とドラゴンkoROBOコンパニオンAIcharacter.aiNomi.aiMETA LOOP DESIGN LTD.MEOHiClubSynClubStarleyCotomoLivetoonkaiwaコンパニオンロボットヒューマノイドRealbotix顔認識Cluade1XNEOジュネーブ大学NadineMIXIPanasonicNICOBOGemini Robotics 1.5XR BlocksLLMERペンシルバニア州立大学SIMA 2日本IBMシリアスゲームセガXDAI俳優世永玲生Adobe MAX 2025Gemini 3GenTabsDiscoイレブンラボジャパン日本郵便年賀状#Geminiで年賀状Nano Banana ProENCODE Jewelry Planner (AI)EncodeRingJewelry DesignerStory Jewelry DesignerAI JEWELRY MODEL中国・西安交通大学LacAIDes工芸宝飾品ソウル文化高等学校MineDojoText-to-VideoOmnimatteZeroSnapX-UniMotionDreamO人工知能のための哲学塾犬飼博士瀬尾浩二郎SteamLarian StudiosDivinityClair Obscur: Expedition 33Indie Game AwardPlaytikaKraftonTranslateGemmaChatGPT ヘルスケアマインスイーパーバイブコーディングGPT-5.1-Codex-MaxClaude Opus 4.5Gemini 3 ProGame ArenaポーカーGemini 3 Pro PreviewGPT-5.2polarixSo Long SuckerTextQuestsProject GenieClaude Opus 4.6快手(Kuaishou)Kling AI
【CEDEC2022】AIでモーションスタイル変換〜バンダイナムコ研究所の取り組み〜
2022.10.26ゲーム

バーチャルなキャラクターの活用の場はゲームやアニメのみに留まらず、いまや動画配信やバーチャル空間のアバターなど、キャラクタービジネスの可能性は多方面へと広がっています。一方で、キャラクターの作り込みには経験やスキルが必要です。バンダイナムコ研究所では、AIを使った人型キャラクターのモーションデータの利活用について研究開発が進められています。CEDEC2022のセッション「モーションキャプチャデータを題材にしたAI研究プロジェクトのポストモーテム – データセット構築からモーションスタイル変換プロジェクトまで」ではバンダイナムコ研究所の髙橋誠史氏、森本直彦氏、株式会社ACESの小林真輝人氏が登壇し、この取り組みを紹介しました。
モーションデータ×AIの潜在ニーズ
バンダイナムコグループのR&Dを担うバンダイナムコ研究所は、ゲーム制作へのAI技術の応用というところで、これまでテキスト(シナリオ、セリフ)、音声(ボイス、効果音、BGM)を対象とした研究を行っています。次の研究開発の対象として着目したのがモーションデータです。とはいえ、ゲームにおけるモーションデータの制作シーンを考えたときにどのような課題があるでしょうか。AIを使うことで何ができるか、どう貢献できるのかを検討するところから始めました。
モーションデータはキャラクターの表現にとって非常に重要な要素です。主役級のキャラクターであれば、モーションアクターをキャスティングして何時間も収録するなどコストをかけて作っていきます。ただし、すべてのキャラクターにそうできるわけではありません。モブ的なキャラクターが大勢、それも老若男女が出てくるとき、そのすべてを収録でカバーすることはまずできません。もし、AIの導入でモーションデータの変換が容易にできれば、ゲームとしての表現が格段に上がるでしょう。
もちろんゲームだけではなく、メタバースの中のアバターにも活用できます。ビジュアルで個性を表現できるようになっていても、動き(モーション)まではカスタマイズが難しいというのが現状です。ちょっとした仕草や動き、そこにも個性を出したいと思う人は多いはずです。あるいは、演者の属性と異なるアバターを演じたいという場合、たとえば男性が美少女のアバターを使って配信するとき、リアルな素の動作を可愛いらしくしたいと思うことがあるでしょう。このように、キャラクターの個性を表現する用途において大きなニーズがあると考えられます。
また、たとえば踊りやパフォーマンスがテーマのゲームなどで、キャラクターが徐々に上手になる過程を描きたいとき、最初は下手に見せたいということがあるでしょう。ボイスチェンジャーのようにモーションの変換ができれば、このようなニーズにも応えることができます。
ニーズがありそうだということで、モーションデータを扱う先行研究を「キャラクターコントロールに関するもの」「モーションをスタイル変換するもの」「自然言語処理によるモーション生成」に分けて調べていきました。
まず、キャラクターコントロールに関する関連研究として、「AI4Animation: Deep Learning for Character Control」が挙げられます。SIGGRAPH 2017で発表された「Phase-Functioned Neural Networks for Character Control(PFNN)」からスタートした一連の研究群です。モーションを学習したモデルからキャラクターのスケルトンアニメーションの制御を行うというもので、ゲームのキャラクター制御にディープラーニングを取り入れたエポックメイキングな研究として知られています。

他にも、GDC 2022のAnimation SummitでElectronic Artsが発表した「’FIFA 22’s’ Hypermotion: Full-Match Mocap Driving Machine Learning Technology」があります。サッカーゲームの選手キャラクターのモーションを機械学習で生成しようという研究で、収録したデータを学習して、ボールに対する選手のインタラクションなどのモーション選定を機械学習で推論するというものです。サッカースタジアムで、実際のゲームの形式でデータを収集するという大規模なプロジェクトです。

次に、モーションをスタイル変換するというカテゴリーです。これは、「歩く」「走る」というモーションに対し、後から「おじいさんの動き」「小さな子どもの動き」というような演技スタイルを加えることで、異なる演技スタイルに変えるというジャンルです。これに関して注目しているものとして2つの研究を取り上げました。
1つが「Unpaired Motion Style Transfer from Video to Animation」です。SIGGRAPH 2020で発表されたもので、現在のAIによるモーションスタイル変換のベースになってる研究です。もう1つが「Motion Puzzle: Arbitrary Motion Style Transfer by Body Part」で、これはUnpaired Motion Style Transferを手や足など部位ごとに適応させるという後続の研究です。2022年の3月に論文が出て、SIGGRAPH 2022で発表されました。

そして、自然言語処理によるモーション生成の先行研究として、「MotionCLIP: Exposing Human Motion Generation to CLIP Space」、「AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars」が紹介されました。巷でもDALL・EやMidjourneyのように、文章を入れたら絵が生成されるAIモデルが流行っていますが、それと同じように、文章をもとにアクションやモーションを生成する研究です。
MotionCLIPはテキストとモーション生成の関係性についての研究で、一方、AvatarCLIPは動作だけでなく、人型のキャラクターに貼り付けるテクスチャー、体型なども文章から生成するというものです。
この分野は今回の取り組みよりも少し先の未来の話だとしながらも、もちろん研究としては視野に入れていると言います。髙橋誠史氏(以下、髙橋氏)は「文章を入れたらいい感じのモーションが生成される」というモデルの実用化まで、あと2、3年というところではないかと言います。

こうした先行研究をサーベイしながら、多数のキャラクター、個性的なメタバースアバターへの長期的な活用につながるということで、モーションスタイル変換の研究を進めていくことになります。実際のゲームに組み込むというより、まずは「データを入れてデータが出てくる」という部分で考えていきました。
今回のプロジェクトの座組みに当たって、「CG」「モーションアニメーション」「AI」の3つの領域の専門家が必要です。内部リソースの稼働の問題もあり、株式会社ACEに協力を依頼するという体制でスタートしました。
モーションスタイル変換とは
では、モーションスタイル変換で何ができるようになるのでしょうか。モーションスタイル変換の技術についてはACEの小林真輝人氏(以下、小林氏)から解説がありました。ACEは2017年創業の東京大学松尾研発のAIスタートアップで、以前からカメラ映像を使った運動認識のAI開発に取り組んでいます。
小林氏は、まず「モーションスタイルの変換(Motion Style Transfer)」というタスクについて、もともとは画像のスタイルトランスファー(Style Transfer)のモーション版にしたものだと言います。つまり、もともとのモーションのコンテンツの情報を維持したままスタイルの情報を変換した新しいモーションを生成するタスクということになります。

画像の場合、たとえば船の画像であれば「船が写っている」というところがコンテンツに当たります。それに対しスタイルは画風のようなもので、スタイルトランスファーというタスクのアウトプットは「コンテンツとスタイルを掛け合わせたトランスファーの結果」です。
モーションの場合は、たとえば歩いているというような「何をしているか」という情報がコンテンツで、スタイルは「どのように歩いているか」という情報になり、アウトプットは「そのスタイルを反映させて歩いているというモーション」になります。より具体的には、属性(年齢や性別など)や性格によるキャラクターの”らしさ”やキャラクターの感情、状態(「元気だ」とか「疲れている」とか)というような情報が具体的なモーションにおけるスタイルに該当します。
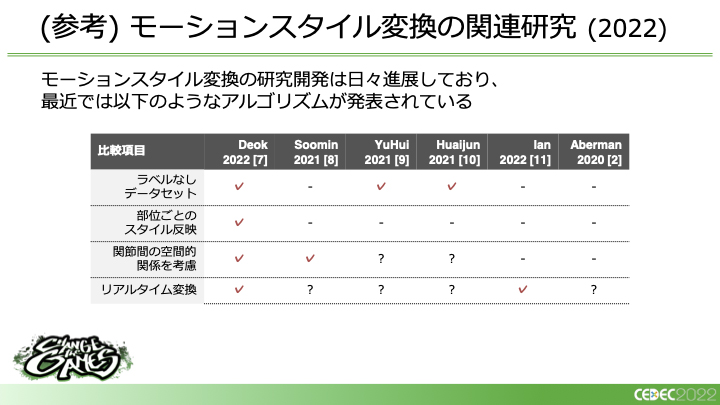
今回、いくつかあるモーションスタイル変換に関する関連研究の中から、Abermanの2020年の論文をベースとして進めることにしました。小林氏は、2020年時点での比較とした上で、Abermanの論文の優れている点として、ペアではない学習データでも学習が可能であるという点、また学習データセットにふくまれていない未学習のスタイルに変換できる点、動画からそのままスタイルが抽出できるといった点を挙げています。それらの利点が、この「キャラクターのモーションの作成」という目的に適切であると考えたのです。

2022年の現在、モーションスタイル変換はさらに研究が進んでおり、前述のMotion Puzzleのように部位ごとにスタイルが反映できたり、関節間の空間的な関係を考慮した変換ができるといったようなところも進んでいるといいます。
独自の改善点:ボーン構造の変更とROOT位置
Abermanの2020年の論文をベースにはしていますが、独自の改善をかなり行っています。
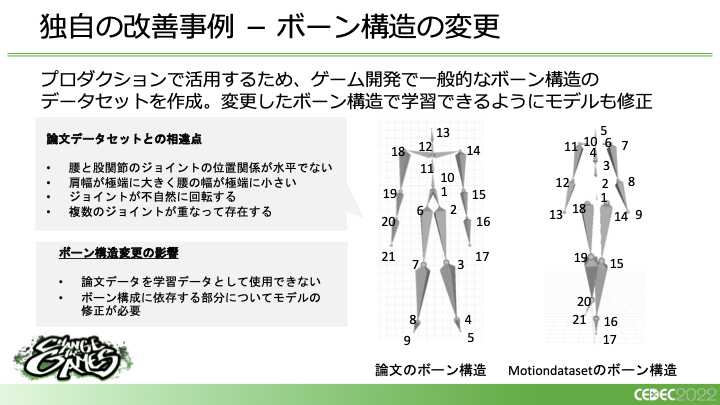
たとえば、ボーン構造の変更です。理由として、アカデミアの研究開発で使われているボーン構造と一般的なゲーム開発などで用いられるボーン構造が異なるということがあります。図の左がもともとの論文で使われているボーン構造で、右がこのプロジェクト内で収録したデータセットで使っているボーン構造です。
そもそものプロポーションが違っているし、腰と股関節のジョイントの位置関係や複数のジョイントが重なって存在したり、回転の定義の仕方などの相違点が多々あります。このまま現在のゲーム開発で使われているボーンにこの左側のボーンで作られたモーションを適用するのは難しいということで、今回、一般的なゲーム開発で用いられているボーン構造で学習データを用意することになりました。学習データだけではなく、変更したボーン構造で学習できるようモデル側の修正も必要でした。
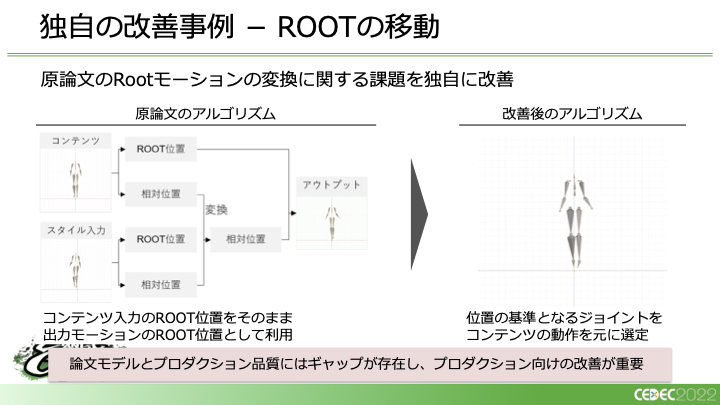
また、アルゴリズムの調整も行っています。もともとの論文では、腰を基準にジョイントの位置情報を取得してモーションスタイルの変換を行います。このとき、腰の位置は入力時のROOTの位置をそのまま適用しています。しかし、そうすると腰の動きに関してスタイルの反映ができないということになります。そこで、位置の基準となるジョイントをコンテンツの動作を元に選定するというアプローチを採りました。
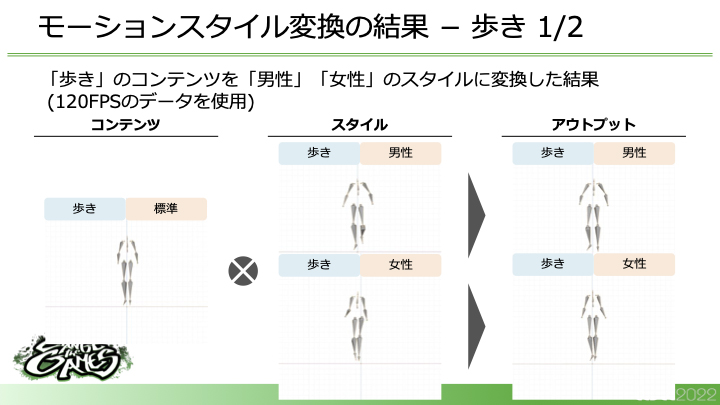
モーションスタイルの変換例
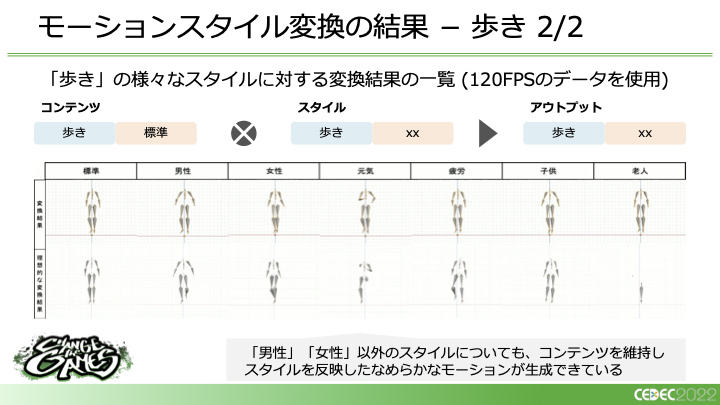
実際に変換した結果は、というと、次の図は「歩き」というコンテンツを男性から女性のスタイルに変換したものです。このように、各スタイルが反映され、かつ、歩いているというコンテンツが維持されたモーションが出力できます。
さらに、「元気」「疲労」「子供」「老人」というスタイルに関しても、コンテンツを維持してスタイルを反映したなめらかなモーションが生成できます。
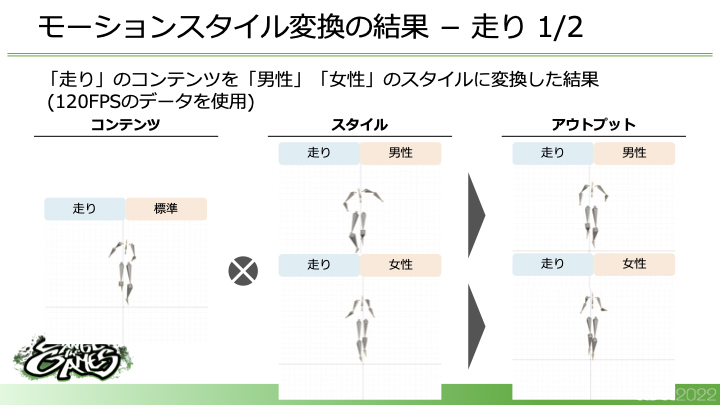
また、「走り」という動作に関してもコンテンツを維持してスタイルを反映した、なめらかなモーションが生成できています。「走り」は「歩き」に比べるとモーションが激しいため、難易度的には少し上がります。

3Dアニメーターがプロジェクトにいる意味
でき上がったモーションや研究開発の過程におけるモーションデータに関するディレクションを監修していたのが、株式会社バンダイナムコ研究所の森本直彦氏(以下、森本氏)です。
森本氏は、バンダイナムコスタジオで長く3Dアニメーターとしてゲーム制作に携わり、現在バンダイナムコ研究所にてアニメーションに関わるR&Dを行っています。まず、今回のプロジェクトにおいて、アニメーションの専門家として3つの役割があったと振り返ります。
- データセット構築のためのモーションキャプチャーに関するすべて:モーションキャプチャーは特殊な分野のため、スケジューリングやキャスティング、収録の進め方など、すべてを担当
- プロジェクト全体を通じて、アウトプットされた結果そのものの品質をある程度見極める:現状のAI研究はそれぞれ非常に興味深い成果を出しているが、実際に商品にしようとしたときに求められる完成度とは別。ときに非常に厳しい意見をフィードバックとして出すことも多々あった
- 専門家としての視点からの気付きやアドバイス:「動き」という点だけに着目してきた長年のアニメーターとしての経験からの知見や気付きをフィードバックする
森本氏は、特にデータセットへの落とし込み(モーションの収録)という点で、今回のプロジェクトで痛感したのは圧倒的なデータ量が必要となるというところだったと言います。手探りで進めていたこともあるとはいえ、たとえば1つのモーション(「歩き」や「走り」など)に対し、スタイルを掛け算していくとすぐに100モーションというような数字になってしまいます。1モーションが5分だとすると100モーションで500分、まともに収録すると収録日数もふくめたモーションキャプチャの費用だけで何千万円という途方もない金額になります。とても研究予算の中に収まりません。
そのため、AIのエンジニアと相談しながら、本当に必要な内容を残しつつ、全体の収録量を現実的なラインに落とし込んでいったそうです。データセットについては次項でも触れますが、データセットを設計する際の気づきとして指摘したのが「モーション(動作そのもの)とアニメーションを意識的に分けて考える」ことです。
たとえば「手を挙げる」動作はモーションです。それに対して、その動作に目的をふくめて表現したものがアニメーションだという考え方です。人間が「手を挙げる」のは遠くにいる人への挨拶であったり、あるいは意見があることを示したい場合だったり、その動作には目的があるわけです。
アニメーターにとっては動作そのものよりもその目的のほうが重要で、動作は目的に付随したものという位置づけです。そういった目的のほうに着目して動きをイメージしたり表現したりということを無意識にしがちなのですが、一方で、AIは学習する際にその動きの意味や目的は認識していません。AIはあくまで動作そのものしか見ないので、AIに学習させる内容を検討する際には人間の側も意識的に動作のほうに着目して考えるようにしなければ、なかなかAIに学習させやすいデータセットは作れないのではないかと言います。
これは非常に興味深い観点で、目的が異なっても同じ「動作」にカテゴライズできるものはあるわけで、そういった整理を事前にしっかりしておくことでノイズの少ない、学習しやすいデータセットを作ることができるのではないかということです。
また、演者(モーションアクター)の難易度が非常に高いというところも留意点として挙げています。ゲームのモーション収録では、せいぜい数百秒の収録です。しかし前述のように、AIが学習するためのデータセットに必要な収録は数時間、場合によっては数十時間かかります。アクターにとっては体力勝負になります。
さらに、ただ動けばいいわけではなくて、スタイルを学習させるためのデータなので、常にスタイルの違いなどを反映した質の高い動きを保ってもらう必要があります。実際、今回のプロジェクトではアクターとして非常に高いスキルを持つ演者に依頼したそうです。ちなみに、収録はバンダイナムコスタジオのモーションキャプチャスタジオで行っています(Viconの光学式モーションキャプチャシステムで収録)。
データセットの設計について
データセットの設計に関する先行研究として参考にしたものとして「Ubisoft La Forge Animation Dataset(”LAFAN1″)」や「100STYLE dataset, I3D 2022」があります。

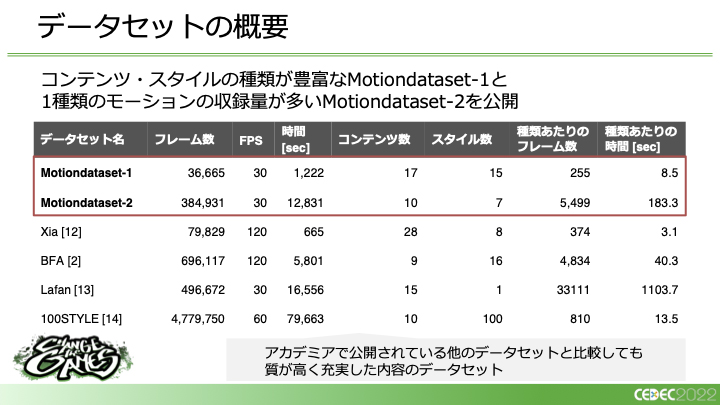
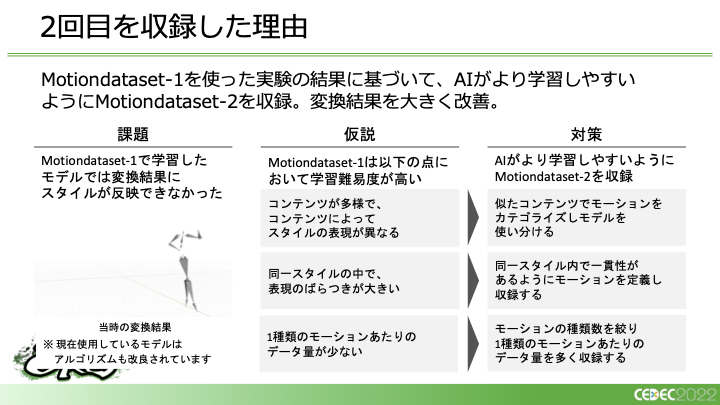
データセットの概要としては、次の図のとおりです。コンテンツやスタイルの種類が豊富なMotiondataset-1と1種類のモーションの収録量が多いMotiondataset-2があります。大きな違いは、Motiondataset-2のほうが1種類あたりのフレーム数が圧倒的に多いという点です。Motiondataset-1とMotiondataset-2があるのは収録を2回行っているからです。要は、Motiondataset-1を使った実験の結果に基づいて、AIがより学習しやすいようにMotiondataset-2を収録した、ということになります。
たとえば「歩く」×「悲しい」と「歩く」×「楽しい」で生成した結果どちらも同じようになってしまう、そうした点を反映するために、同一スタイルの中の表現のばらつきを解消する、1種類あたりのデータ量を多くするなどして収録を行いました。
また、変換に使っているモデルのアルゴリズムの部分も改良し、学習難易度を下げるために似たようなコンテンツでカテゴライズし、モデルを使い分けるという形にしています。その結果、アウトプットの質も大きく改善したと言います。
モーションデータのデータセットを設計する上で、今後の課題として高橋氏が指摘するのは、データのラベリングやアノテーションの仕方といった部分です。今回のデータセットに関しては「歩く」「走る」というようなアクションそのもののコンテキストと、男性女性老人若者というようなスタイルをファイル名に入れるという命名規則で十分でしたが、より複雑な処理をしようとした場合、ラベリングやアノテーションの仕方が課題になってくると考えています。
バンダイナムコ研究所では、今回のプロジェクトで使用したデータセットを公開しています。 モーション変換アルゴリズムだけでなく、こうしたさまざまな先行研究を利用する中で、自分たちも何か業界やアカデミアに返せるものがないかということで、今回、データセットの公開を行ったそうです。

今回のプロジェクトはデータセットを公開したところが終了ではなく、この後、これを活用していくというところが自分たちの技術開発において礎になると考えています。今、文章から絵を自動生成するAIモデルが世の中を席巻していますが、これはモーションの世界でも起こるでしょう。そうしたとき、ツールの形で利用するのか、自分たちでモーションデータを収録して研究開発するのか、2つの選択肢があるが、どちらにしてもアンテナを張っておくという意味でこうした研究開発の意味は大きいと高橋氏は言います。
今後も、こうしたチャレンジを続けて、データセットの更新や論文化を進めていく予定です。
Writer:大内孝子



 RANKING
RANKING



